C3: Compilation and Code Generation for Invasive Programs
Principal Investigators:
Prof. G. Snelting, Prof. J. Teich
Scientific Researchers:
Jorge A. Echavarria, A. Fried, S. Graf, PD Dr. F. Hannig, M. Witterauf
Abstract
Project C3 considers compilation and code generation as well as program transformation and optimisation techniques for non-regular (procedural) code as well as for task-level and regularly-structured (i.e. loop-level) code.
In the first funding phase, a compiler for the concrete language defined in Project A1 has been developed. The compiler is based on an existing X10 compiler, but has been extended with new transformation phases to support tightly coupled processor arrays (TCPAs) as well as SPARC processors and i-Cores through libFIRM. For TCPAs, the loop compiler LoopInvader was developed that detects and extracts nested loop programs from a given X10 input program and transforms these loop nests into single assignment code. A breakthrough in symbolic compilation techniques was achieved here by being able to determine an optimal mapping of loop iterations to processors as well as their latency-optimal scheduling in dependence of an unknown number of available processors (claim size). For RISC cores, a new transformation phase builds the intermediate representation FIRM and then generates code using a newly developed SPARC back end. Additionally, an invasive X10 run-time library has been created to efficiently map X10 language constructs to operating system interfaces.
In the second funding phase, a major focus of research has been the quest for (higher) predictability of non-functional aspects of invasive parallel program execution, i.e. performance, fault tolerance, and security. Based on the pioneering work from the first phase, we investigated new compilation techniques in the polyhedron model for the resource-adaptive parallel execution of invasive loop programs on processor arrays. Furthermore, in order to counter the increasing proneness to errors of modern, complex systems we developed new fault tolerance measures. Here, we proposed new techniques that leverage the advantages of invasive computing to implement fault tolerance on TCPAs adaptively and on demand. Regarding the code generation for RISC targets, we focused on verification and optimisation, both on the level of the intermediate representation (IR) and in the language runtime. Furthermore, we proposed a novel technique to avoid serialization when copying pointered data structures between shared memory partitions on non-cache-coherent architectures.
In the third funding phase, the major focus will be run-time enforcement of multiple non-functional execution qualities such as user-specified performance and energy corridors. The major research topics in the second phase include (a) constant latency/throughput loop processing, (b) approximate loop processing including language extensions to specify imprecise loop variables, (c) a symbolic code generator for TCPA targets shall be developed that will support the symbolic loop parallelisation techniques developed in the previous funding phases, (d) compiler optimisations for the i-Core, (e) optimisations for FPGAs, (f) discovery of invasive programming patterns.
Synopsis
This project investigates compilation techniques for invasive computing architectures. Its central role is the development of a compiler framework for code generation as well as program transformations and optimisations for a wide range of heterogeneous invasive architectures, including RISC cores, TCPAs (tightly coupled processor arrays), and i-Core reconfigurable processors.
In Phase III, a major focus of research will be the theme of run-time enforcement of multiple non-functional execution qualities, such as user-specified performance and energy corridors. It is well known that in many programs, a considerable portion of execution time is spent in the processing of inner loops. To enforce any non-functional requirements on an application at run time therefore heavily implies the need for run-time requirement enforcement techniques specific to loops. Loops, however, inherently add uncertainty to an application because their bounds are often parameters, that means unknown until run time. Our goal is to develop compiler techniques that allow for the run-time enforcement of execution qualities such as latency bounds of loop execution on TCPAs under the uncertainty of loop bounds that become known only at run time. Here, we plan to investigate mainly two particular techniques: compilation of constant-latency loops and approximate loop processing. While constant-latency loops facilitate run-time enforcement of latency requirements by splitting a problem into smaller, more fine-grained loops, approximate loop processing trades off the accuracy of results for the sake of improved other non-functional qualities.
Additionally, our research focuses on symbolic code generation. So far in our research, we developed theories and theorems for automatic symbolic parallelisation of loop programs by determining latency-minimal symbolic schedules. But how can we generate machine code according to a symbolic schedule where the schedule of iterations of a loop nest materialises only at run time? This yet unanswered, but important question poses unique challenges because TCPAs by design have only highly limited instruction memories and run-time compilation is not feasible. We therefore aim to implement a symbolic code generation back end, which emits symbolic code chunks that will be composed on-the-fly at the time of loading the programs and in a way that minimises any run-time overhead and code size per processing element.
Overview of compiler framework
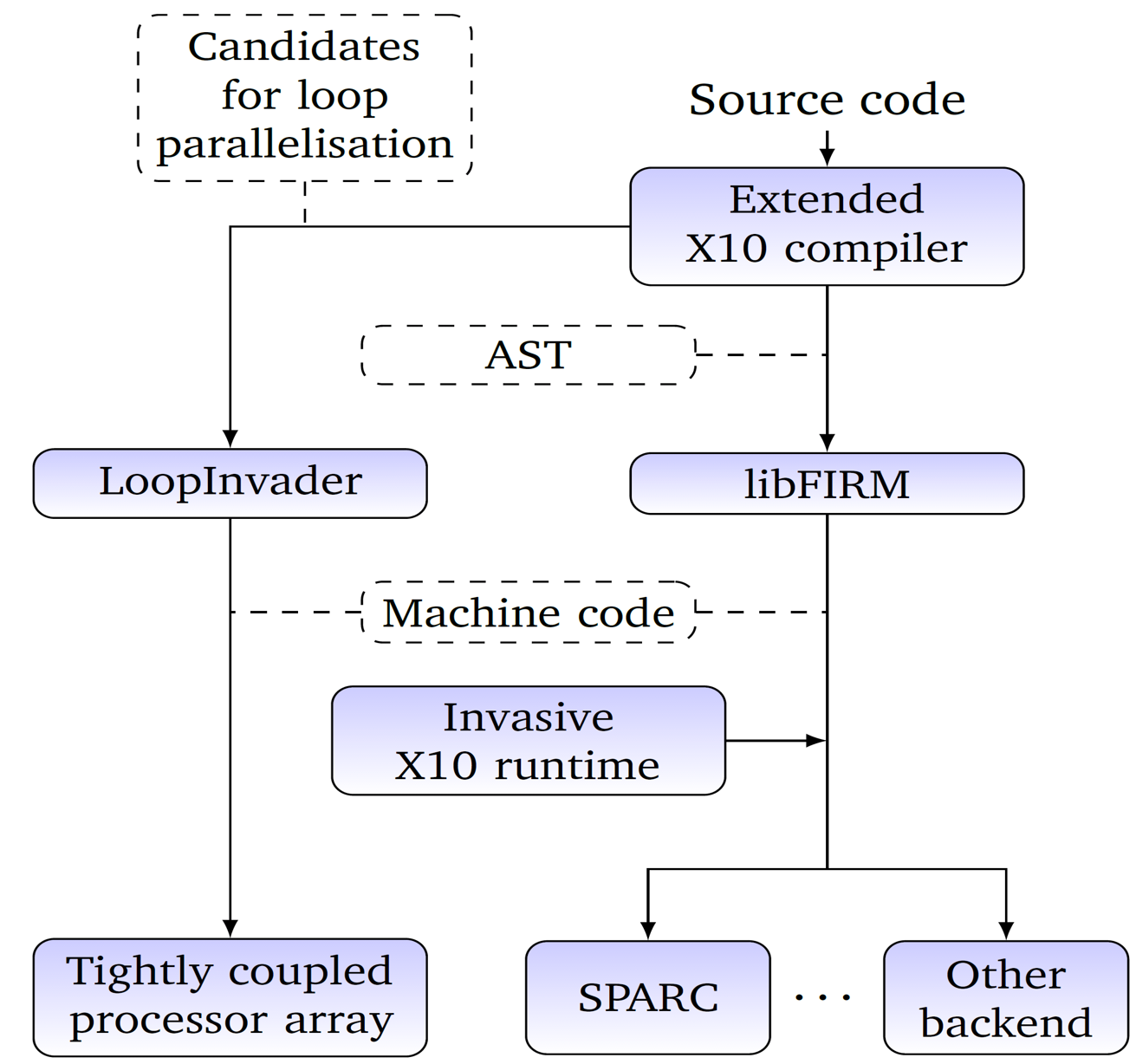
Overview of the compiler framework for invasive computing. The front end is based on the X10 compiler, which is open source. The back end for SPARC targets is generated using the FIRM compiler infrastructure. The back end for invasive parallel loop codes to run on tightly coupled processor arrays (TCPAs) is provided by the tool LoopInvader.
Approach
Symbolic loop Parallelization
We investigated new compilation techniques in the polyhedron model for the resource-adaptive parallel execution of invasive loop programs on processor arrays. The goal was to find optimal symbolic assignments and schedules of loop iterations at compile time for an array of processors where the number of available cores is only known at run time. This symbolic loop parallelisation step is essential for invasive programming on MPSoCs, because the claimed region of processors, whose shape and size determines the forms of tiles during parallelisation, is not known at compile time. Furthermore, it avoids just-in-time compilation as well as the need of a compiler resident on the MPSoC. Based on the pioneering work on symbolic loop parallelisation of the previous phase, we considered extensions towards locally parallel, globally sequential (LPGS) schemes. Here, invasive loop nests are mapped onto a processor array of unknown size at compile time while being independent of the problem size. The loop iterations within a tile are assigned to one processor each for parallel execution, yet the tiles are started to be executed in a sequential order. We proved analytically that it is possible to derive such parametrised LPGS schedules statically by using a mixed compile-/run-time approach. However, while satisfying memory requirements, the resulting schedules may result in I/O requirements that exceed the capacities of the processor array architecture. To match the required I/O-capacities and local memory sizes at a fine scale, we proposed a symbolic multi-level parallelisation approach that balances necessary I/O-bandwidth and memory size to fit a given TCPA architecture.
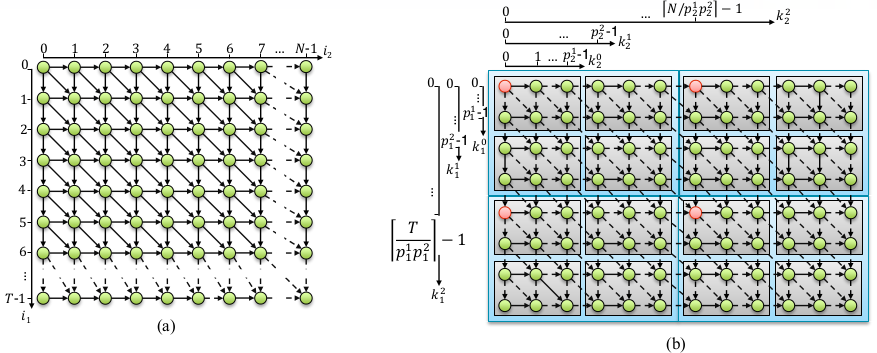
Iteration space of a 2D loop nest. Each node represents an iteration of the loop program. Each directed edge represents a data dependence between two iterations. (b) Iteration space hierarchically and symbolically tiled on 2 levels.
This is demonstrated in the figure above, where an iteration space of a 2D loop nest is hierarchically and symbolically tiled on 2 levels, represented by the gray and blue tiles, respectively. Next, in order to assign to each iteration a start time, we analytically proved that it is possible to derive a scheduling scheme that assigns start times to iterations within tiles that are scheduled sequentially on the first and last level and parallel start times to all tile origins on all the other levels.
Fault-tolerant loop processing
Since the feature sizes of silicon devices have continued to shrink, it is imperative to counter the increasing proneness to errors of modern, complex systems by applying appropriate fault tolerance measures. In order to achieve this goal, we proposed new techniques that leverage the advantages of invasive computing to implement fault tolerance on TCPAs (as investigated in Project B2) adaptively and on demand. Here, we have presented a compile-time transformation that introduces modular redundancy into a loop program to protect it against soft errors.
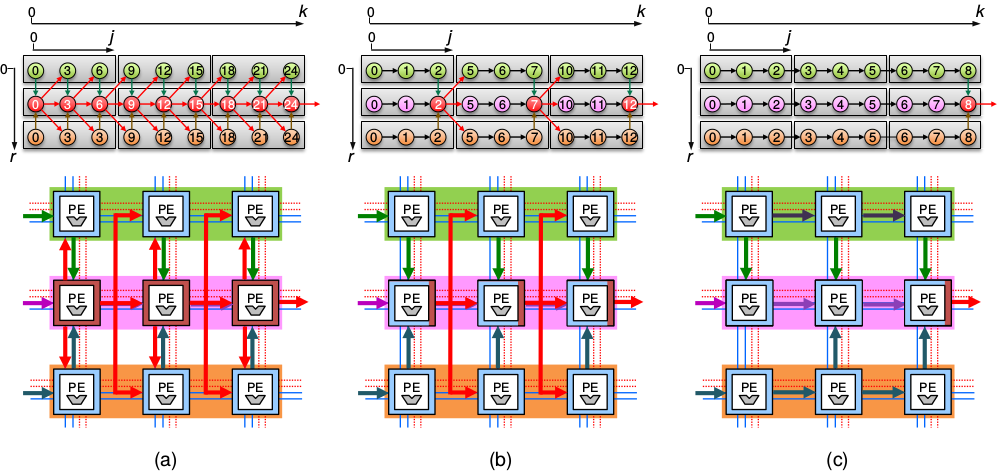
Possible voting schemes for TMR with voting placement (a) for every loop iteration (immediate voting), (b) at the border of each PE's iteration space (early voting), and (c) at the border of the array (late voting). The replicated iteration space of a one-dimensional loop nest is also shown. The coloured edges represent the extra dependencies introduced by voting: red edges show the propagation of the voting results, green and brown edges show the propagation of results from the first and third replica to the second replica where voting on them takes place.
The above figure illustrates our approach, where an invasive loop application claims three linear array replicas (shown in different colours) in order to implement a TMR scheme. It uses the abundant number of processing elements (PEs) within a TCPA to claim not only one region of a processor array, but instead two (for double modular redundancy (DMR)) or three (for triple modular redundancy (TMR)) contiguous neighbouring regions of PEs. Next,voting operations into the replicated loop program. Here, we proposed three different variants to detect, respectively correct errors: for each variable to be protected, (a) in every loop iteration (immediate voting), (b) once per PE (early voting), and (c) at the border of the allocated processor array region (late voting). Each of these variants exhibits a different trade-off in terms of latency (time to finish computation) and error detection latency (EDL) (time to detect a fault).
Integrated Code Generation for FPGAs
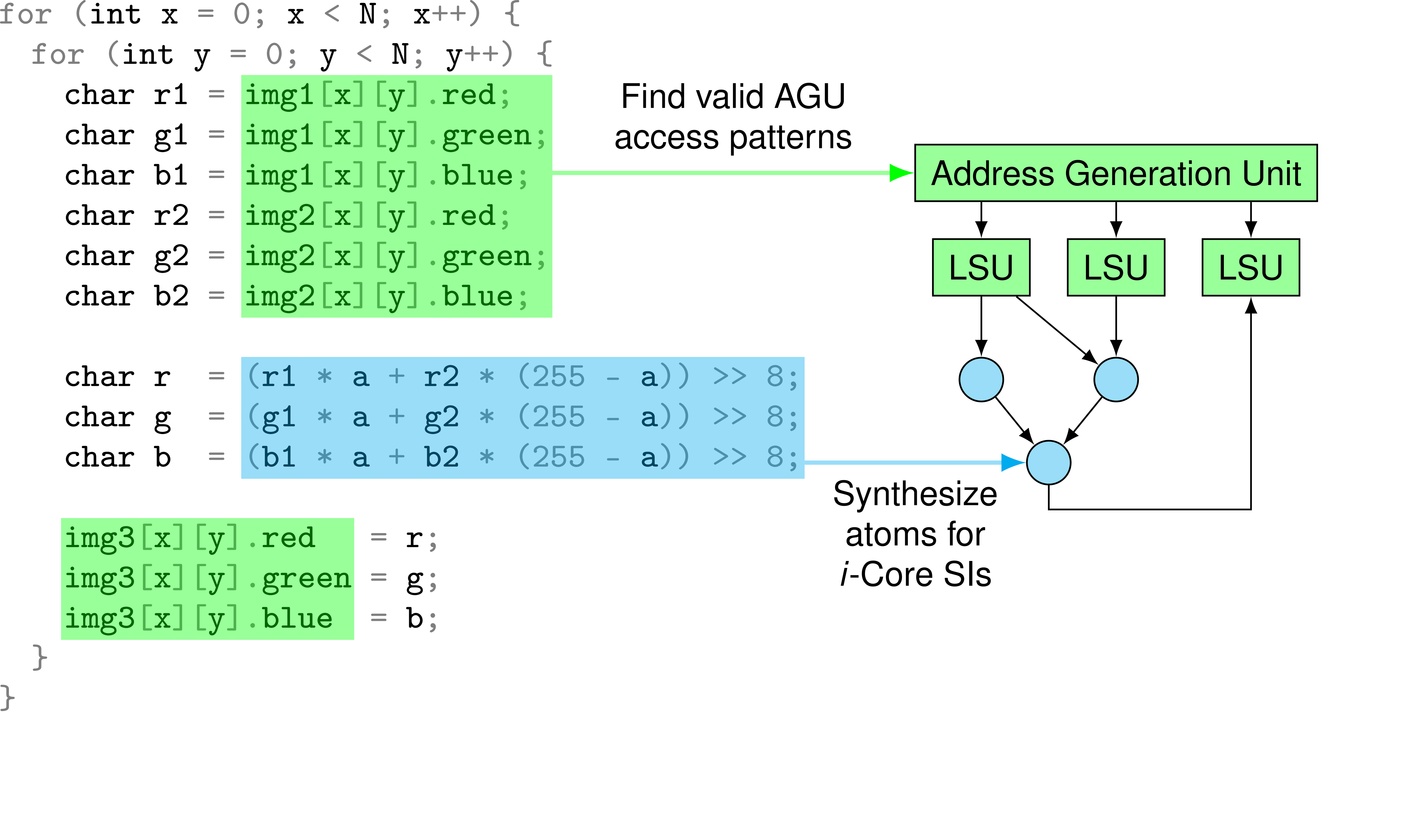
The elements of a Special Instruction: The Address Generation Units stream data from and to main memory in regular patterns. The computation to be done on this data is compiled to a hardware description language, which is then synthesised into the i-Core's reconfigurable fabric.
We have already investigated accelerating applications through the use of Special Instructions (SIs) in the previous funding phases, specifically the i-Core developed in Project B1. The basic idea behind SIs is to identify a particular computation that could accelerate an application if it were (partly) implemented in hardware. The desired functionality is then implemented in an SI by specifying a configuration for the i-Core's FPGA fabrics, and a micro-program that connects the fabrics and streams data from and to main memory. From the point of view of the application, the SI appears as an additional assembly instruction, which invokes the micro-program and executes the specified computation on the i-Core. At the DFG assessment of Phase II, we were able to demonstrate the benefit of SIs in a simulation of wave propagation.
However, efficient SIs currently still have to be written separately in a hardware description language. This is because the usual compiler optimizations assume a classical CPU as their target. Especially in the embedded sector, this is an increasingly unrealistic assumption. We will therefore investigate compiler optimizations specific to FPGA targets, which will enable us to compile the same high-level source code to fast software as well as efficient virtual hardware.
A comprehensive overview of the major achievements of the first and second funding phase can be found by accessing Project C3 first phase and Project C3 second phase websites.
Publications
| [1] | Gregor Snelting, Jürgen Teich, Andreas Fried, Frank Hannig, and Michael Witterauf. Compilation and code generation for invasive programs. In Jürgen Teich, Jörg Henkel, and Andreas Herkersdorf, editors, Invasive Computing, pages 309–333. FAU University Press, August 16, 2022. [ DOI ] |
| [2] | Nidhi Anantharajaiah, Tamim Asfour, Michael Bader, Lars Bauer, Jürgen Becker, Simon Bischof, Marcel Brand, Hans-Joachim Bungartz, Christian Eichler, Khalil Esper, Joachim Falk, Nael Fasfous, Felix Freiling, Andreas Fried, Michael Gerndt, Michael Glaß, Jeferson Gonzalez, Frank Hannig, Christian Heidorn, Jörg Henkel, Andreas Herkersdorf, Benedict Herzog, Jophin John, Timo Hönig, Felix Hundhausen, Heba Khdr, Tobias Langer, Oliver Lenke, Fabian Lesniak, Alexander Lindermayr, Alexandra Listl, Sebastian Maier, Nicole Megow, Marcel Mettler, Daniel Müller-Gritschneder, Hassan Nassar, Fabian Paus, Alexander Pöppl, Behnaz Pourmohseni, Jonas Rabenstein, Phillip Raffeck, Martin Rapp, Santiago Narváez Rivas, Mark Sagi, Franziska Schirrmacher, Ulf Schlichtmann, Florian Schmaus, Wolfgang Schröder-Preikschat, Tobias Schwarzer, Mohammed Bakr Sikal, Bertrand Simon, Gregor Snelting, Jan Spieck, Akshay Srivatsa, Walter Stechele, Jürgen Teich, Furkan Turan, Isaías A. Comprés Ureña, Ingrid Verbauwhede, Dominik Walter, Thomas Wild, Stefan Wildermann, Mario Wille, Michael Witterauf, and Li Zhang. Invasive Computing. FAU University Press, August 16, 2022. [ DOI ] |
| [3] | Christian Heidorn, Nicolai Meyerhöfer, Christian Schinabeck, Frank Hannig, and Jürgen Teich. Hardware-Aware Evolutionary Filter Pruning. In International Conference on Embedded Computer Systems: Architectures, Modeling and Simulation (SAMOS), July 2022. [ DOI ] |
| [4] | Jürgen Teich. Enforcement of non-functional program requirements on MPSOCs. Keynote, HiPEAC Computing Week, Lyon, France, October 25, 2021. |
| [5] | Michael Witterauf. A Compiler for Symbolic Code Generation for Tightly Coupled Processor Arrays. Dissertation, Hardware/Software Co-Design, Department of Computer Science, Friedrich-Alexander-Universität Erlangen-Nürnberg, Germany, October 18, 2021. [ arXiv ] |
| [6] | Armin Schuster, Christian Heidorn, Marcel Brand, Oliver Keszöcze, and Jürgen Teich. Design space exploration of time, energy, and error rate trade-offs for CNNs using accuracy-programmable instruction set processors. In Joint European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD), September 2021. [ DOI ] |
| [7] | Christian Heidorn, Dominik Walter, Yunus Emre Candir, Frank Hannig, and Jürgen Teich. Hand sign recognition via deep learning on tightly coupled processor arrays. In Proceedings of the 31st International Conference on Field-Programmable Logic and Applications (FPL), page 388. IEEE, August 2021. [ DOI ] |
| [8] | Michael Witterauf, Dominik Walter, Frank Hannig, and Jürgen Teich. Symbolic loop compilation for tightly coupled processor arrays. ACM Transactions on Embedded Computing Systems (TECS), 2021. |
| [9] | Oliver Keszöcze, Marcel Brand, Michael Witterauf, Christian Heidorn, and Jürgen Teich. Aarith: An Arbitrary Precision Number Library. In ACM/SIGAPP Symposium On Applied Computing, 2021. [ DOI ] |
| [10] | Dominik Walter, Michael Witterauf, and Jürgen Teich. Real-time scheduling of I/O transfers for massively parallel processor arrays. In Proceedings of the 18th ACM-IEEE International Conference on Formal Methods and Models for System Design (MEMOCODE), pages 1–11. IEEE, December 2020. [ DOI ] |
| [11] | M. Akif Özkan, Arsène Pérard-Gayot, Richard Membarth, Philipp Slusallek, Roland Leissa, Sebastian Hack, Jürgen Teich, and Frank Hannig. AnyHLS: High-level synthesis with partial evaluation. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD), 39(11), October 2020. [ DOI ] |
| [12] | T. K. R. Arvind, Marcel Brand, Christian Heidorn, Srinivas Boppu, Frank Hannig, and Jürgen Teich. Hardware implementation of hyperbolic tangent activation function for floating point formats. In Proceedings of the 24th International Symposium on VLSI Design and Test (VDAT). IEEE, July 2020. [ DOI ] |
| [13] | Christian Heidorn, Frank Hannig, and Jürgen Teich. Design space exploration for layer-parallel execution of convolutional neural networks on CGRAs. In Proceedings of the 23rd International Workshop on Software and Compilers for Embedded Systems (SCOPES), pages 26–31. ACM, May 2020. [ DOI ] |
| [14] | Michael Witterauf, Frank Hannig, and Jürgen Teich. Polyhedral fragments: An efficient representation for symbolically generating code for processor arrays. In Proceedings of the 17th ACM-IEEE International Conference on Formal Methods and Models for System Design (MEMOCODE), pages 8:1–8:10. ACM, October 2019. [ DOI ] |
| [15] | Christian Heidorn, Michael Witterauf, Frank Hannig, and Jürgen Teich. CNN-inference on coarse-grained reconfigurable arrays under throughput constraints. Invited talk, 4th Tensilica Day – Trends in Modern Design of Configurable Processors, Leibnitz University Hannover, Germany, September 23, 2019. |
| [16] | Jürgen Teich. Efficient treatment of uncertainty in system reliability analysis using importance measures. Invited Talk at the Workshop Intelligent Methods for Test and Reliability, Schloss Dagstuhl, September 12, 2019. |
| [17] | Faramarz Khosravi. System-Level Reliability Analysis and Optimization in the Presence of Uncertainty. Dissertation, Hardware/Software Co-Design, Department of Computer Science, Friedrich-Alexander-Universität Erlangen-Nürnberg, Germany, August 5, 2019. |
| [18] | Christian Heidorn, Michael Witterauf, Frank Hannig, and Jürgen Teich. Efficient mapping of CNNs onto tightly coupled processor arrays. Journal of Computers (JCP), 14(8):541–556, August 2019. [ DOI ] |
| [19] | Marcel Brand, Michael Witterauf, Éricles R. Sousa, Alexandru Tanase, Frank Hannig, and Jürgen Teich. *-Predictable MPSoC execution of real-time control applications using invasive computing. Concurrency and Computation: Practice and Experience, February 2019. [ DOI ] |
| [20] | Sven Rheindt, Andreas Fried, Oliver Lenke, Lars Nolte, Thomas Wild, and Andreas Herkersdorf. NEMESYS: Near-memory graph copy enhanced system-software. In MEMSYS 19: The International Symposium on Memory Systems, Washington DC, 2019. |
| [21] | Michael Witterauf and Jürgen Teich. Run-time requirement enforcement for loop programs on processor arrays. In Proceedings of the 16th ACM-IEEE International Conference on Formal Methods and Models for System Design (MEMOCODE), pages 1–11, October 2018. [ DOI ] |
| [22] | Jürgen Teich. Run-time application mapping in many-core architectures. Invited Talk National University of Singapore, August 24, 2018. |
| [23] | Jürgen Teich. Mixed static/dynamic application mapping for NoC-based MPSoCs with guarantees on timing, reliability and security. Invited Talk Nanyang Technological University, Singapore, August 23, 2018. |
| [24] | Jürgen Teich. Hybrid application mapping for NoC-based MPSoCs with guarantees on timing, reliability and security. Invited Talk University of New South Wales, Australia, July 31, 2018. |
| [25] | Oliver Reiche. A Domain-Specific Language Approach for Designing and Programming Heterogeneous Image Systems. Dissertation, Hardware/Software Co-Design, Department of Computer Science, Friedrich-Alexander-Universität Erlangen-Nürnberg, Germany, July 5, 2018. |
| [26] | Éricles R. Sousa, Michael Witterauf, Marcel Brand, Alexandru Tanase, Frank Hannig, and Jürgen Teich. Invasive computing for predictability of multiple non-functional properties: A cyber-physical system case study. In Proceedings of the 29th Annual IEEE International Conference on Application-specific Systems, Architectures and Processors (ASAP). IEEE, July 2018. [ DOI ] |
| [27] | Jürgen Teich. Methodologies for application mapping for noc-based mpsocs. Keynote, Adaptive Many-Core Architectures and Systems workshop, York, UK, June 14, 2018. |
| [28] | Bo Qiao, Oliver Reiche, Frank Hannig, and Jürgen Teich. Automatic kernel fusion for image processing DSLs. In Proceedings of the 21st International Workshop on Software and Compilers for Embedded Systems (SCOPES), pages 76–85. ACM, May 2018. [ DOI ] |
| [29] | Christian Schmitt, Frank Hannig, and Jürgen Teich. A Target Platform Description Language for Parallel Code Generation. In Workshop Proceedings of the 31st GI/ITG International Conference on Architecture of Computing Systems (ARCS), pages 59–66, Berlin, April 2018. VDE VERLAG GmbH. |
| [30] | Alexandru Tanase, Frank Hannig, and Jürgen Teich. Symbolic Parallelization of Nested Loop Programs. Springer, February 2018. [ DOI ] |
| [31] | Andreas Weichslgartner, Stefan Wildermann, Michael Glaß, and Jürgen Teich. Invasive Computing for Mapping Parallel Programs to Many-Core Architectures. Springer, January 15, 2018. [ DOI ] |
| [32] | Sebastian Buchwald, Andreas Fried, and Sebastian Hack. Synthesizing an instruction selection rule library from semantic specifications. In Proceedings of 2018 IEEE/ACM International Symposium on Code Generation and Optimization, CGO '18, New York, NY, USA, 2018. ACM. [ DOI ] |
| [33] | Alexander Pöppl, Marvin Damschen, Florian Schmaus, Andreas Fried, Manuel Mohr, Matthias Blankertz, Lars Bauer, Jörg Henkel, Wolfgang Schröder-Preikschat, and Michael Bader. Shallow water waves on a deep technology stack: Accelerating a finite volume tsunami model using reconfigurable hardware in invasive computing. In Dora B. Heras, Luc Bougé, Gabriele Mencagli, Emmanuel Jeannot, Rizos Sakellariou, Rosa M. Badia, Jorge G. Barbosa, Laura Ricci, Stephen L. Scott, Stefan Lankes, and Josef Weidendorfer, editors, Euro-Par 2017: Proceedings of the 10th Workshop on UnConventional High Performance Computing (UCHPC 2017), Lecture Notes in Computer Science (LNCS), pages 676–687, Cham, 2018. Springer International Publishing. |
| [34] | Oliver Reiche, Mehmet Akif Özkan, Frank Hannig, Jürgen Teich, and Moritz Schmid. Loop Parallelization Techniques for FPGA Accelerator Synthesis. Journal of Signal Processing Systems, 90:3–27, 2018. [ DOI ] |
| [35] | Éricles Sousa, Arindam Chakraborty, Alexandru Tanase, Frank Hannig, and Jürgen Teich. TCPA Editor: A design automation environment for a class of coarse-grained reconfigurable arrays. Demo Night at the International Conference on Reconfigurable Computing and FPGAs (ReConFig), December 2017. |
| [36] | Éricles Sousa, Alexandru Tanase, Frank Hannig, and Jürgen Teich. A reconfigurable memory architecture for system integration of coarse-grained reconfigurable arrays. In Proceedings of the International Conference on Reconfigurable Computing and FPGAs (ReConFig). IEEE, December 2017. [ DOI ] |
| [37] | Oliver Reiche, M. Akif Özkan, Richard Membarth, Jürgen Teich, and Frank Hannig. Generating FPGA-based image processing accelerators with Hipacc. In Proceedings of the International Conference On Computer Aided Design (ICCAD). IEEE, November 2017. Invited Paper. |
| [38] | Alexandru Tanase. Symbolic Parallelization of Nested Loop Programs. Dissertation, Hardware/Software Co-Design, Department of Computer Science, Friedrich-Alexander-Universität Erlangen-Nürnberg, Germany, September 19, 2017. |
| [39] | Oliver Reiche, Christof Kobylko, Frank Hannig, and Jürgen Teich. Auto-vectorization for image processing DSLs. In Proceedings of the ACM SIGPLAN/SIGBED Conference on Languages, Compilers and Tools for Embedded systems (LCTES). ACM, June 2017. [ DOI ] |
| [40] | Manuel Mohr and Carsten Tradowsky. Pegasus: Efficient data transfers for PGAS languages on non-cache-coherent many-cores. In Design, Automation and Test in Europe Conference Exhibition (DATE), pages 1781–1786, March 30, 2017. |
| [41] | Soonhoi Ha and Jürgen Teich, editors. The Handbook of Hardware/Software Codesign. Springer, 2017. [ DOI ] |
| [42] | Manuel Mohr and Carsten Tradowsky. Pegasus: Efficient data transfers for PGAS languages on non-cache-coherent many-cores. In Proceedings of Design, Automation and Test in Europe Conference Exhibition (DATE), pages 1781–1786. IEEE, 2017. [ DOI ] |
| [43] | Alexandru Tanase, Michael Witterauf, Jürgen Teich, and Frank Hannig. Symbolic multi-level loop mapping of loop programs for massively parallel processor arrays. ACM Transactions on Embedded Computing Systems (TECS), 17(2):31:1–31:27, 2017. [ DOI ] |
| [44] | Jürgen Teich. Invasive computing – editorial. it – Information Technology, 58(6):263–265, November 24, 2016. [ DOI ] |
| [45] | Vivek Singh Bhadouria, Alexandru Tanase, Moritz Schmid, Frank Hannig, Jürgen Teich, and Dibyendu Ghoshal. A novel image impulse noise removal algorithm optimized for hardware accelerators. Journal of Signal Processing Systems, 89(2):225–242, November 1, 2016. [ DOI ] |
| [46] | Vahid Lari, Andreas Weichslgartner, Alex Tanase, Michael Witterauf, Faramarz Khosravi, Jürgen Teich, Jürgen Becker, Jan Heißwolf, and Stephanie Friederich. Providing fault tolerance through invasive computing. it – Information Technology, 58(6):309–328, October 19, 2016. [ DOI ] |
| [47] | Stefan Wildermann, Michael Bader, Lars Bauer, Marvin Damschen, Dirk Gabriel, Michael Gerndt, Michael Glaß, Jörg Henkel, Johny Paul, Alexander Pöppl, Sascha Roloff, Tobias Schwarzer, Gregor Snelting, Walter Stechele, Jürgen Teich, Andreas Weichslgartner, and Andreas Zwinkau. Invasive computing for timing-predictable stream processing on MPSoCs. it – Information Technology, 58(6):267–280, September 30, 2016. [ DOI ] |
| [48] | Jürgen Teich, Michael Glaß, Sascha Roloff, Wolfgang Schröder-Preikschat, Gregor Snelting, Andreas Weichslgartner, and Stefan Wildermann. Language and compilation of parallel programs for *-predictable MPSoC execution using invasive computing. In Proceedings of the 10th IEEE International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSoC), pages 313–320, Lyon, France, September 2016. [ DOI ] |
| [49] | Jürgen Teich. Predictability, fault tolerance, and security on demand using invasive computing. Invited Talk, University of Lübeck, Germany, July 29, 2016. |
| [50] | Michael Witterauf, Alexandru Tanase, Frank Hannig, and Jürgen Teich. Modulo scheduling of symbolically tiled loops for tightly coupled processor arrays. In Proceedings of the 27th IEEE International Conference on Application-specific Systems, Architectures and Processors (ASAP), pages 58–66. IEEE, July 2016. [ DOI ] |
| [51] | Jürgen Teich. Invasive Computing - The DFG Transregional Research Center 89. DTC 2016, The Munich Workshop on Design Technology Coupling, Munich, Germany, June 30, 2016. |
| [52] | Jürgen Teich. Predictable MPSoC stream processing using invasive computing. Seminar Talk, Electrical and Computer Engineering, The University of Texas at Austin, USA, June 6, 2016. |
| [53] | Jürgen Teich. Adaptive restriction and isolation for predictable MPSoC stream procesing. Invited Talk, DATE 2016 Friday Workshop on Resource Awareness and Application Autotuning in Adaptive and Heterogeneous Computing, Dresden, Germany, March 18, 2016. |
| [54] | Alexandru Tanase, Michael Witterauf, Éricles R. Sousa, Vahid Lari, Frank Hannig, and Jürgen Teich. LoopInvader: A compiler for tightly coupled processor arrays. Tool Presentation at the University Booth at Design, Automation and Test in Europe (DATE), Dresden, Germany, March 2016. [ .pdf ] |
| [55] | Jürgen Teich. Symbolic loop parallelization for adaptive multi-core systems - recent advances and benefits. Keynote, IMPACT 2016, the 6th International Workshop on Polyhedral Compilation Techniques, 19 January, 2016, Prague, Czech Republic, January 19, 2016. |
| [56] | Jürgen Teich. The role of restriction and isolation for increasing the predictability of MPSoC stream processing. Keynote, 8th Workshop on Rapid Simulation and Performance Evaluation: Methods and Tools (RAPIDO 2016), Prague, Czech Republic, January 18, 2016. |
| [57] | Sebastian Buchwald, Denis Lohner, and Sebastian Ullrich. Verified construction of static single assignment form. In Manuel Hermenegildo, editor, 25th International Conference on Compiler Construction, CC 2016, pages 67–76. ACM, 2016. [ DOI ] |
| [58] | Oliver Reiche, Konrad Häublein, Marc Reichenbach, Moritz Schmid, Frank Hannig, Jürgen Teich, and Dietmar Fey. Synthesis and optimization of image processing accelerators using domain knowledge. Journal of Systems Architecture (JSA), December 2015. [ DOI ] |
| [59] | Vahid Lari, Jürgen Teich, Alexandru Tanase, Michael Witterauf, Faramarz Khosravi, and Brett H. Meyer. Techniques for on-demand structural redundancy for massively parallel processor arrays. Journal of Systems Architecture (JSA), 61(10):615–627, November 2015. [ DOI ] |
| [60] | Alexandru Tanase, Michael Witterauf, Jürgen Teich, and Frank Hannig. Symbolic loop parallelization for balancing I/O and memory accesses on processor arrays. In Proceedings of the 13th ACM-IEEE International Conference on Formal Methods and Models for System Design (MEMOCODE), pages 188–197. IEEE, September 2015. [ DOI ] |
| [61] | Sebastian Buchwald, Manuel Mohr, and Ignaz Rutter. Optimal shuffle code with permutation instructions. In Frank Dehne, Jörg-Rüdiger Sack, and Ulrike Stege, editors, Algorithms and Data Structures, volume 9214 of Lecture Notes in Computer Science, pages 528–541. Springer International Publishing, August 2015. [ DOI ] |
| [62] | Moritz Schmid. Rapid Prototyping for Hardware Accelerators in the Medical Imaging Domain. Dissertation, Hardware/Software Co-Design, Department of Computer Science, Friedrich-Alexander-Universität Erlangen-Nürnberg, Germany, July 24, 2015. |
| [63] | Michael Witterauf, Alexandru Tanase, Frank Hannig, and Jürgen Teich. Adaptive fault tolerance in tightly coupled processor arrays with invasive computing. In Proceedings of the 11th International Summer School on Advanced ComputerArchitecture and Compilation for High-Performance and Embedded Systems (ACACES), pages 205–208, July 2015. |
| [64] | Alexandru Tanase, Michael Witterauf, Jürgen Teich, Frank Hannig, and Vahid Lari. On-demand fault-tolerant loop processing on massively parallel processor arrays. In Proceedings of the 26th IEEE International Conference on Application-specific Systems, Architectures and Processors (ASAP), pages 194–201. IEEE, July 2015. [ DOI ] |
| [65] | Moritz Schmid, Oliver Reiche, Frank Hannig, and Jürgen Teich. Loop coarsening in C-based high-level synthesis. In Proceedings of the 26th IEEE International Conference on Application-specific Systems, Architectures and Processors (ASAP), pages 166–173. IEEE, July 2015. |
| [66] | Manuel Mohr, Sebastian Buchwald, Andreas Zwinkau, Christoph Erhardt, Benjamin Oechslein, Jens Schedel, and Daniel Lohmann. Cutting out the middleman: OS-level support for X10 activities. In Proceedings of the fifth ACM SIGPLAN X10 Workshop, X10 '15, pages 13–18, New York, NY, USA, June 14, 2015. ACM. [ DOI ] |
| [67] | Michael Witterauf, Alexandru Tanase, Jürgen Teich, Vahid Lari, Andreas Zwinkau, and Gregor Snelting. Adaptive fault tolerance through invasive computing. In Proceedings of the 2015 NASA/ESA Conference on Adaptive Hardware and Systems (AHS), pages 1–8. IEEE, June 2015. [ DOI ] |
| [68] | Jürgen Teich. Adaptive isolation for predictable mpsoc stream processing. In Proceedings of the 18th International Workshop on Software and Compilers for Embedded Systems (SCOPES 2015), pages 1–2, June 2015. [ DOI ] |
| [69] | Jürgen Teich. Adaptive isolation for predictable mpsoc stream processing. Keynote, SCOPES 2015, 18th International Workshop on Software and Compilers for Embedded Systems, Schloss Rheinfels, St. Goar, Germany, June 2, 2015. |
| [70] | Vahid Lari, Alexandru Tanase, Jürgen Teich, Michael Witterauf, Faramarz Khosravi, Frank Hannig, and Brett H. Meyer. A co-design approach for fault-tolerant loop execution on coarse-grained reconfigurable arrays. In Proceedings of the 2015 NASA/ESA Conference on Adaptive Hardware and Systems (AHS), pages 1–8. IEEE, June 2015. [ DOI ] |
| [71] | Jürgen Teich, Srinivas Boppu, Frank Hannig, and Vahid Lari. Compact code generation and throughput optimization for coarse-grained reconfigurable arrays. In Wayne Luk and George A. Constantinides, editors, Transforming Reconfigurable Systems: A Festschrift Celebrating the 60th Birthday of Professor Peter Cheung, chapter 10, pages 167–206. Imperial College Press, London, UK, April 2015. [ DOI ] |
| [72] | Sebastian Buchwald. Optgen: A generator for local optimizations. In Björn Franke, editor, Proceedings of the International Conference on Compiler Construction (CC), volume 9031 of Lecture Notes in Computer Science, pages 171–189. Springer Berlin Heidelberg, April 2015. [ DOI ] |
| [73] | Jürgen Teich. Invasive computing. Invited Talk, SE 2015, Software Engineering and Management, Special Session Software Engineering in der DFG, Dresden, Germany, March 19, 2015. |
| [74] | Gregor Snelting. Understanding probabilistic software leaks. Science of Computer Programming, 97, Part 1(0):122–126, January 2015. Special Issue on New Ideas and Emerging Results in Understanding Software. [ DOI ] |
| [75] | Dennis Giffhorn and Gregor Snelting. A new algorithm for low-deterministic security. International Journal of Information Security, 14(3):263–287, 2015. [ DOI ] |
| [76] | Jürgen Teich. Reconfigurable computing for mpsoc. Invited Lecture, Winter School Design and Applications of Multi Processor System on Chip, Tunis, Tunesia, November 26, 2014. |
| [77] | Jürgen Teich. Invasive computing – concepts and benefits. Keynote, DASIP 2014, Conference on Design and Architectures for Signal and Image Processing, Madrid, Spain, October 8, 2014. |
| [78] | Alexandru Tanase, Michael Witterauf, Jürgen Teich, and Frank Hannig. Symbolic inner loop parallelisation for massively parallel processor arrays. In Proceedings of the 12th ACM-IEEE International Conference on Formal Methods and Models for System Design (MEMOCODE), pages 219–228, October 2014. [ DOI ] |
| [79] | Éricles Sousa, Deepak Gangadharan, Frank Hannig, and Jürgen Teich. Runtime reconfigurable bus arbitration for concurrent applications on heterogeneous MPSoC architectures. In Proceedings of the EUROMICRO Digital System Design Conference (DSD), pages 74–81. IEEE, August 2014. [ DOI ] |
| [80] | Jürgen Teich. Foundations and benefits of invasive computing. Seminar, Mc Gill University, Montreal, July 29, 2014. |
| [81] | Jürgen Teich, Alexandru Tanase, and Frank Hannig. Symbolic mapping of loop programs onto processor arrays. Journal of Signal Processing Systems, 77(1–2):31–59, July 11, 2014. [ DOI ] |
| [82] | Srinivas Boppu, Frank Hannig, and Jürgen Teich. Compact code generation for tightly-coupled processor arrays. Journal of Signal Processing Systems, 77(1–2):5–29, May 31, 2014. [ DOI ] |
| [83] | Jürgen Teich. Introduction to invasive computing. Workshop on Resource Awareness and Adaptivity in Multi-Core Computing (Racing 2014), Paderborn, Germany, Tutorial Talk, May 29, 2014. |
| [84] | Jürgen Teich. Foundations and benefits of invasive computing. University of Bologna, Italy, Invited Talk in the Seminar Series Trends in Electronics, May 23, 2014. |
| [85] | Frank Hannig and Jürgen Teich, editors. Proceedings of the First Workshop on Resource Awareness and Adaptivity in Multi-Core Computing (Racing 2014). May 2014. [ arXiv ] |
| [86] | Vahid Lari, Alexandru Tanase, Frank Hannig, and Jürgen Teich. Massively parallel processor architectures for resource-aware computing. In Proceedings of the First Workshop on Resource Awareness and Adaptivity in Multi-Core Computing (Racing 2014), pages 1–7, May 2014. [ arXiv ] |
| [87] | Deepak Gangadharan, Alexandru Tanase, Frank Hannig, and Jürgen Teich. Timing analysis of a heterogeneous architecture with massively parallel processor arrays. In DATE Friday Workshop on Performance, Power and Predictability of Many-Core Embedded Systems (3PMCES). ECSI, March 28, 2014. [ http ] |
| [88] | Éricles Sousa, Vahid Lari, Johny Paul, Frank Hannig, Jürgen Teich, and Walter Stechele. Resource-aware computer vision application on heterogeneous multi-tile architecture. Hardware and Software Demo at the University Booth at Design, Automation and Test in Europe (DATE), Dresden, Germany, March 2014. |
| [89] | Gregor Snelting, Dennis Giffhorn, Jürgen Graf, Christian Hammer, Martin Hecker, Martin Mohr, and Daniel Wasserrab. Checking probabilistic noninterference using joana. IT - Information Technology, 2014. invited article, currently under review. [ .pdf ] |
| [90] | Frank Hannig, Vahid Lari, Srinivas Boppu, Alexandru Tanase, and Oliver Reiche. Invasive tightly-coupled processor arrays: A domain-specific architecture/compiler co-design approach. ACM Transactions on Embedded Computing Systems (TECS), 13(4s):133:1–133:29, 2014. [ DOI ] |
| [91] | Jürgen Teich. Invasive computing – the quest for many-core efficiency and predictability. Keynote Talk, Sixth Swedish Workshop on Multicore Computing, Halmstad, Sweden, November 25, 2013. |
| [92] | Jürgen Teich. Invasive computing - the quest for many-core efficiency and predictability. Invited Talk, 5th tubs.CITY Symposium, Managing change and autonomy or critical applications, Braunschweig, Germany, October 30, 2013. |
| [93] | Éricles Sousa, Alexandru Tanase, Frank Hannig, and Jürgen Teich. A prototype of an adaptive computer vision algorithm on an MPSoC architecture. In Proceedings of the Conference on Design and Architectures for Signal and Image Processing (DASIP), pages 361–362. IEEE, October 2013. |
| [94] | Éricles Sousa, Alexandru Tanase, Frank Hannig, and Jürgen Teich. Accuracy and performance analysis of harris corner computation on tightly-coupled processor arrays. In Proceedings of the Conference on Design and Architectures for Signal and Image Processing (DASIP), pages 88–95. IEEE, October 2013. |
| [95] | Manuel Mohr, Artjom Grudnitsky, Tobias Modschiedler, Lars Bauer, Sebastian Hack, and Jörg Henkel. Hardware acceleration for programs in SSA form. In International Conference on Compilers, Architecture and Synthesis for Embedded Systems (CASES), Montreal, Canada, October 2013. [ DOI ] |
| [96] | Jürgen Teich. The invasive computing paradigm as a solution for highly adaptive and efficient multi-core systems. Talk, Special Session on Run-Time Adaption for Highly-Compley Multi-Core Systems, CODES+ISSS 2013, Montral, Canada, September 30, 2013. |
| [97] | Alexandru Tanase, Vahid Lari, Frank Hannig, and Jürgen Teich. Exploitation of quality/throughput tradeoffs in image processing through invasive computing. In Proceedings of the International Conference on Parallel Computing (ParCo), pages 53–62, September 2013. [ DOI ] |
| [98] | Jürgen Teich, Alexandru Tanase, and Frank Hannig. Symbolic parallelization of loop programs for massively parallel processor arrays. In Proceedings of the 24th IEEE International Conference on Application-specific Systems, Architectures and Processors (ASAP), pages 1–9. IEEE, June 2013. Best Paper Award. [ DOI ] |
| [99] | Srinivas Boppu, Frank Hannig, and Jürgen Teich. Loop program mapping and compact code generation for programmable hardware accelerators. In Proceedings of the 24th IEEE International Conference on Application-specific Systems, Architectures and Processors (ASAP), pages 10–17. IEEE, June 2013. [ DOI ] |
| [100] | Éricles Sousa, Alexandru Tanase, Vahid Lari, Frank Hannig, Jürgen Teich, Johny Paul, Walter Stechele, Manfred Kröhnert, and Tamim Asfour. Acceleration of optical flow computations on tightly-coupled processor arrays. In Proceedings of the 25th Workshop on Parallel Systems and Algorithms (PARS), volume 30 of Mitteilungen – Gesellschaft für Informatik e. V., Parallel-Algorithmen und Rechnerstrukturen, pages 80–89. Gesellschaft für Informatik e.V., April 2013. |
| [101] | Frank Hannig. Resource-aware computing on domain-specific accelerators. In Proceedings of the 10st Workshop on Optimizations for DSP and Embedded Systems (ODES), page 35. ACM, February 24, 2013. Keynote. [ DOI ] |
| [102] | Jürgen Teich. Safe(r) loop computations on multi-cores. Invited Talk, 2nd Workshop on Design Tools and Architectures for Multi-Core Embedded Computing Platforms (DITAM 2013), Berlin, Germany, January 22, 2013. |
| [103] | Hans-Joachim Bungartz, Christoph Riesinger, Martin Schreiber, Gregor Snelting, and Andreas Zwinkau. Invasive computing in HPC with X10. In X10 Workshop (X10'13), X10 '13, pages 12–19, New York, NY, USA, 2013. ACM. [ DOI ] |
| [104] | Matthias Braun, Sebastian Buchwald, Sebastian Hack, Roland Leißa, Christoph Mallon, and Andreas Zwinkau. Simple and efficient construction of static single assignment form. In Ranjit Jhala and Koen Bosschere, editors, Compiler Construction, volume 7791 of LNCS, pages 102–122. Springer, 2013. [ DOI ] |
| [105] | Frank Hannig. Why do we see more and more domain-specific accelerators in multi-processor systems? Guest Lecture at University of California, Riverside in CS 287 Colloquium in Computer Science, Riverside, CA, USA, November 9, 2012. |
| [106] | Frank Hannig. Invasive tightly-coupled processor arrays. Talk, 1st International Workshop on Domain-Specific Multicore Computing (DSMC) at International Conference on Computer-Aided Design (ICCAD), San Jose, CA, USA, November 8, 2012. |
| [107] | Jürgen Teich, Andreas Weichslgartner, Benjamin Oechslein, and Wolfgang Schröder-Preikschat. Invasive computing – concepts and overheads. In Proceedings of the Forum on Specification and Design Languages (FDL), pages 193–200, September 2012. |
| [108] | Alexandru Tanase, Frank Hannig, and Jürgen Teich. Symbolic loop parallelization of static control programs. In Proceedings of the 8th International Summer School on Advanced Computer Architecture and Compilation for High-Performance and Embedded Systems (ACACES), pages 33–36, July 2012. |
| [109] | Alexandru Tanase, Frank Hannig, and Jürgen Teich. Towards symbolic loop parallelization for tightly-coupled processor arrays. Work-In-Progress Presentation at the 49th Design Automation Conference (DAC), San Francisco, USA, June 2012. |
| [110] | Jürgen Teich. Hardware/software co-design: The past, present, and predicting the future. Proceedings of the IEEE, 100(Centennial-Issue):1411–1430, May 2012. [ DOI ] |
| [111] | Richard Membarth, Frank Hannig, Jürgen Teich, Mario Körner, and Wieland Eckert. Generating Device-specific GPU Code for Local Operators in Medical Imaging. In Proceedings of the 26th IEEE International Parallel & Distributed Processing Symposium (IPDPS), pages 569–581, May 2012. [ DOI ] |
| [112] | Matthias Braun, Sebastian Buchwald, Manuel Mohr, and Andreas Zwinkau. An X10 compiler for invasive architectures. Technical Report 9, Karlsruhe Institute of Technology, 2012. [ http ] |
| [113] | Srinivas Boppu, Frank Hannig, Jürgen Teich, and Roberto Perez-Andrade. Towards symbolic run-time reconfiguration in tightly-coupled processor arrays. In Proceedings of the International Conference on Reconfigurable Computing and FPGAs (ReConFig), pages 392–397. IEEE, November 2011. [ DOI ] |
| [114] | Jürgen Teich. Programming invasively parallel – an introduction. Pervasive Parallelism Laboratory (PPL) Seminar Talk, Stanford University, CA, USA, July 25, 2011. |
| [115] | Jürgen Teich. Invasive parallel computing – an introduction. Par Lab and AMP Lab Seminar Talk, UC Berkeley, CA, USA, July 22, 2011. |
| [116] | Georgia Kouveli, Frank Hannig, Jan-Hugo Lupp, and Jürgen Teich. Towards resource-aware programming on Intel's single-chip cloud computer processor. In 3rd Many-core Applications Research Community (MARC) Symposium, volume 7598 of KIT Scientific Reports, pages 111–114. KIT Scientific Publishing, July 2011. |
| [117] | Jürgen Teich, Jörg Henkel, Andreas Herkersdorf, Doris Schmitt-Landsiedel, Wolfgang Schröder-Preikschat, and Gregor Snelting. Invasive computing: An overview. In Michael Hübner and Jürgen Becker, editors, Multiprocessor System-on-Chip – Hardware Design and Tool Integration, pages 241–268. Springer, Berlin, Heidelberg, 2011. [ DOI ] |
| [118] | Sebastian Buchwald, Andreas Zwinkau, and Thomas Bersch. SSA-based register allocation with PBQP. In Jens Knoop, editor, Proceedings of the International Conference on Compiler Construction (CC), volume 6601 of LNCS, pages 42–61. Springer, 2011. [ DOI ] |
| [119] | Frank Hannig. Retargetable mapping of loop programs on coarse-grained reconfigurable arrays. Talk, International Conference on Hardware-Software Codesign and System Synthesis (CODES+ISSS), Scottsdale, AZ, USA, October 26, 2010. |
| [120] | Tom Vander Aa, Praveen Raghavan, Scott Mahlke, Bjorn De Sutter, Aviral Shrivastava, and Frank Hannig. Compilation techniques for CGRAs: Exploring all parallelization approaches. In Proceedings of the International Conference on Hardware-Software Codesign and System Synthesis (CODES+ISSS), pages 185–186. ACM, October 2010. [ DOI ] |
| [121] | Jürgen Teich. Invasive computing – basic concepts and foreseen benefits. Artist Network of Excellence on Embedded System Design Summer School Europe 2010, Autrans, France, Invited Tutorial, September 7, 2010. |
| [122] | Christian Hammer and Gregor Snelting. Flow-sensitive, context-sensitive, and object-sensitive information flow control based on program dependence graphs. International Journal of Information Security, 8(6):399–422, December 2009. [ DOI ] |
| [123] | Amouri Abdulazim, Farhadur Arifin, Frank Hannig, and Jürgen Teich. FPGA implementation of an invasive computing architecture. In Proceedings of the IEEE International Conference on Field Programmable Technology (FPT), pages 135–142. IEEE, December 2009. [ DOI ] |
| [124] | Farhadur Arifin, Richard Membarth, Amouri Abdulazim, Frank Hannig, and Jürgen Teich. FSM-controlled architectures for linear invasion. In Proceedings of the 17th IFIP/IEEE International Conference on Very Large Scale Integration (VLSI-SoC), pages 59–64, October 2009. [ DOI ] |
| [125] | Matthias Braun and Sebastian Hack. Register spilling and live-range splitting for SSA-form programs. In Proceedings of the International Conference on Compiler Construction (CC), pages 174–189. Springer, March 2009. [ DOI ] |
| [126] | Jürgen Teich. Invasive algorithms and architectures. it - Information Technology, 50(5):300–310, 2008. |
| [127] | Sebastian Hack, Daniel Grund, and Gerhard Goos. Register allocation for programs in SSA-form. In Andreas Zeller and Alan Mycroft, editors, Proceedings of the International Conference on Compiler Construction (CC), volume 3923 of Lecture Notes In Computer Science (LNCS), pages 247–262. Springer, March 2006. [ DOI ] |