B2: Invasive Tightly-Coupled Processor Arrays
Principal Investigators:
Scientific Researchers
M. Brand, C. Heidorn, D. Walter, PD Dr. F. Hannig
Abstract
Project B2 investigates invasive computing on tightly coupled processor arrays (TCPAs). These have been shown to provide highly energy-efficient and, at the same time, timing-predictable acceleration for many computationally intensive applications that may be expressed by nested loops from diverse areas such as scientific computing and image and signal processing, to name a few.
In the first funding phase, concepts for hardware-controlled invasion through a cycle-wise propagation of invasion control signals between neighbouring processing elements (PEs) have been investigated. Not only may such decentralised parallel invasion strategies reduce the invasion overhead by two orders of magnitude w.r.t. a centralised software-based approach. Even bounds on the invasion time of invading N processing elements in Ο(N) clock cycles have been shown to be achievable. For invasion control, two variants, namely finite state machine based (FSM-based) and programmable variants have been proposed, and different 1D and 2D invasion strategies were evaluated. Moreover, the self-adaptive nature of invasive computing was also exploited for the purpose of dynamic power management by controlling the wake up as well as the powering down regions of processors directly by the invade and retreat signals, respectively. As invades and retreats are initiated application-driven, a TCPA may therefore nicely adopt itself to the application requirements in terms of power needs. Finally, a first invasive TCPA prototype for basic visual computing algorithms was demonstrated in cooperation with Project Z2 on the CHIPit prototyping system.
In the second funding phase, a major focus of research has been the quest for (higher) predictability of non-functional aspects of invasive parallel program execution, i.e. performance, fault tolerance, and energy consumption. Invasive computing and architectures naturally lend to these goals through perfect isolation of applications by not sharing resources. Our major investigations were centred on non-functional objectives with a particular focus on safe(r) loop processing , i.e., the investigation of fault-tolerance schemes that become active on-demand and energy reduction in view of the emerging problem of dark silicon. In the latter area, we were able to show that TCPAs provide an excellent IP in the fight against dark silicon by not only being able to save dynamic, but also static power by powering a claimed TCPA region up only at invade-time. In case of high reliability requirements, fault-tolerance schemes such as DMR and TMR are needed. Here, we proposed to avoid modifying the hardware architecture of TCPAs, but instead implement redundancy only based on the principles of invasion of either (a) a non-redundant, (b) a dual-replicated, or even (c) a triple-replicated array instance copy for computing a parallel loop nest in lock-step mode. Designs on how to achieve this including (a) signal replication of input and output signal streams, (b) voting (hard-wired vs. SW-based voting), as well as (c) error detection and recovery techniques (memory and communication error protection hardware).
In the third funding phase, the problem of run-time enforcement of non-functional execution qualities also for parallel loop programs executed on TCPAs is in the focus of this project. In order to enforce a given set of non-functional requirements of a loop nest when executed in parallel on an invasive TCPA, an overprovisioning of resources (the invaded region of TCPA processors) shall be greatly avoided. To do so, completely novel techniques shall be developed summarised as (a) self-invasion of claim sizes of latency-bound programs, (b)self-Power Adjustment, (c) self-selection of redundancy scheme. Other planned investigations include the exploitation of approximate loop computing on TCPAs in order to stay within execution time bounds or to save energy and invasive floating-point TCPAs that will open a new dimension of applications.
Synopsis
The goal of this project is to provide concepts and solutions for invasive tightly coupled processor arrays (TCPAs) that may be
embedded as high-speed and low-energy tiles within a heterogeneous MPSoC.
They may be found on many MPSoC platforms to provide area- and power-efficient computing structures for fine- to medium-grained
highly-parallel computations such as specified by nested loop programs. Domains of particular interest are image and signal processing, linear algebra type of computations, and many others.
Here, they play out their full advantage of a cycle-wise data processing and delivering results over dedicated regular interconnect links with very low overhead.
In our project, each node of a TCPA is a customisable VLIW processor.
In phase III, the major focus of research is the problem of run-time enforcement of non-functional execution qualities also for parallel loop programs executed on TCPAs. In order to enforce a given set of non-functional requirements such as on the latency, power, or reliability of a loop nest when executed in parallel on an invasive TCPA, an overprovisioning of resources (the invaded region of TCPA processors) has to be avoided. Here, the size of the claim to be invaded shall be determined at run time such to neither overprovision nor underutilise TCPA resources. Alternatively or in combination with the above run-time computation of a required minimal claim size to be invaded for satisfying requirements on latency, also hardware concepts for auto-adjustment of the power to stay in a desired power corridor or to minimise the needed power may be envisioned.
We have shown in the second funding phase that TCPAs allow the fully deterministic and fully timing-predictable execution of nested loop programs due to their inherent nature to execute a globally synchronous clocked parallel schedule of a given loop nest. However, due to the physical limits of TCPA I/O buffers, a continuous refilling of the input buffers as well as a continuous DMA to drain full output buffers at the border of the array is often needed. Accordingly, these DMAs must be scheduled with deadlines to have data available perfectly in-time, else the TCPA will immediately stall and the assumption of a fully predictable processing of loop programs is not valid any more. Here, hardware concepts shall be developed to schedule all I/O DMA transfers readily enough.
Currently, our TCPAs benefit from single-cycle processing of all instructions, all on integer data. Yet, many applications in science and cyber-physical systems such as driver assistance systems require to process floating-point data types, often even with adjustable precision, either in order to save energy, or to adhere to specific sensor and actuator formats. Here, a novel processing element (PE) structure for TCPAs that supports multi-cycle as well as variable precision floating-point formats including a detailed analysis of potential design area overheads, instruction memory sizes, and expected energy and latency savings as well as approximation errors shall be provided. With the same goal to dynamically save energy when executing loop programs in parallel on 100 or more PEs, we would like to exploit concepts of the recent research area of approximate computing in order to guarantee the enforceability of performance and/or energy requirements for a wide range of uncertain inputs by computing complex floating-point instructions in specialised functional units (FPUs) imprecisely.
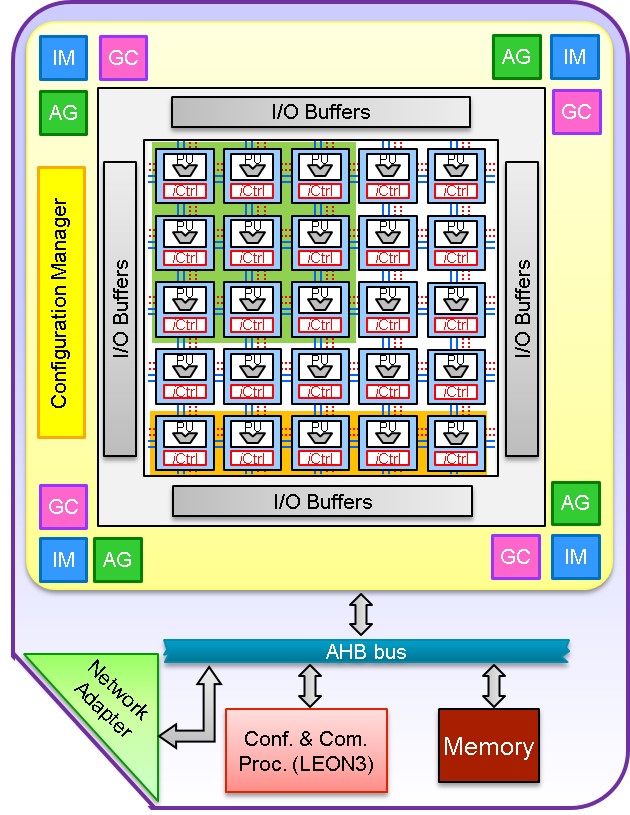
Invasive TCPA tile architecture
|
Processing elements: Light weight, programmable tightly-coupled processor array having VLIW architecture Reconfiguration and Communication Processor: Controls the communication between the different architectural components of the TCPA tile and reconfigures the processor arraye Configuration Manager: Configures the processor array for different applications Global Controller (GC): Controls the execution of loop programs by sending appropriate control signals to the array Reconfigurable I/O Buffers and address generators (AG): Data buffers of surrounding the processor array responsible for proper data feeds into the array Invasion Manager (IM): Handles the invasion requests of a TCPA and keeps track of the availability of processor regions for admission of new applications within the array. Invasion Controller (iCtrl): Each PE consists not only of a VLIW CPU but an additional controller that implements multiple invasion strategies that may capture PEs either in a linear or rectangular connected regions. Network Adapter: Interface between the iNoC and TCPA tile |
|
Safe(r) loops – Fault-tolerant parallel loop processing
The high integration density of future multicore systems will inevitably lead to an increased vulnerability of the circuits, e.g., a malfunction due to thermal effects, circuitry wear-outs, or cosmic radiation. However, instead of analysing error and fault effects on single cores, we lifted for the first time well-known fault tolerance schemes such as dual (DMR) and triple modular redundancy (TMR) to the level of loop programs and their parallel processing on multicores. Here, we investigated approaches in which, based on application requirements on reliable execution, an invasive loop program may request to switch on and off fault tolerance schemes for error detection and/or correction of certain parts or a parallel loop application as a whole. Without creating any inefficiency for error detection circuits in our hardware, the regular structure of TCPAs does ideally offer an application to claim (a) a non-redundant, (b) a dual-replicated, or even (c) a triple-replicated array instance for computing the parallel program in lock-step mode which are illustrated in the figure below. The necessary compiler support for loop program transformation for fault-tolerant loop computation and simulation has been developed by Project C3 and Project C2, respectively.
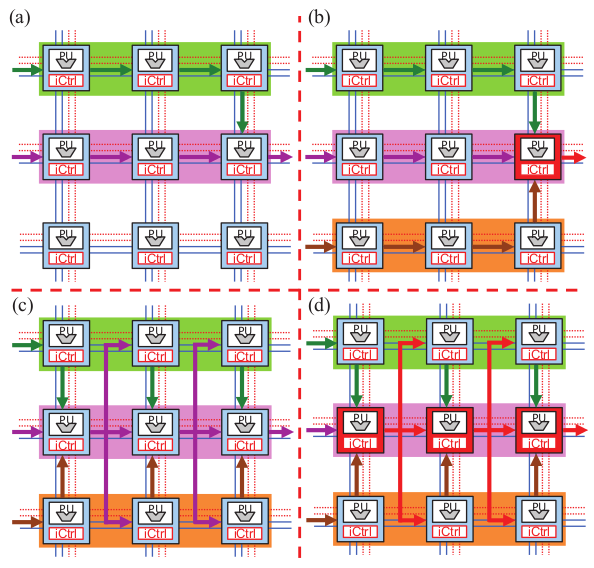
On demand of safety requirements, a certain redundancy scheme must be activated. On an invasive TCPA, this is achieved by claiming identical subarrays to realise (a) (DMR), and (b)-(d) TMR. Comparison and voting are performed at the array boundary (late) in (a) and (b), respectively. In (c) and (d), voting is performed in software, respectively in hardware, inside the processor array (immediate) for earlier detection/correction of potential errors.
The essential ideas of our proposed approach is too claim double or triple times the number of processors in a contiguous region to allow for the detection or correction, respectively, of soft errors, e.g., single event upsets (SEUs) automatically. A safety-critical loop program is transformed first so to execute a lock-step parallel schedule of two (for DMR) or three (for TMR) identical copies of a parallel loop. Based on a compile-time quantitative analysis of the execution time and reliability gains in terms of probability of failure in dependence of observed soft error rate during operation, we showed how a suitable redundancy scheme might be selected at run time to enforce a desired safety-level. An example of such quantitative analysis is plotted in the figure below in terms of the probability of failure per hour (PFH) for a matrix-matrix multiplication kernel. The figures show PFH values depending on the size of PEs in each replica and two different soft error rates at the level of each PE, i.e., 2,000 failures in time (FIT). Also annotated in the figures are the margins of the four safety integrity levels (SIL), namely, SIL 1, SIL 2, SIL 3, SIL 4 defined by the IEC 61508 standard. The PFH values for the non-redundant variant would not meet any SIL requirement and redundancy schemes have to be applied if needed by the application. If less than ten PEs are claimed, the DMR/TMR (Late) version may satisfy few SIL requirements.
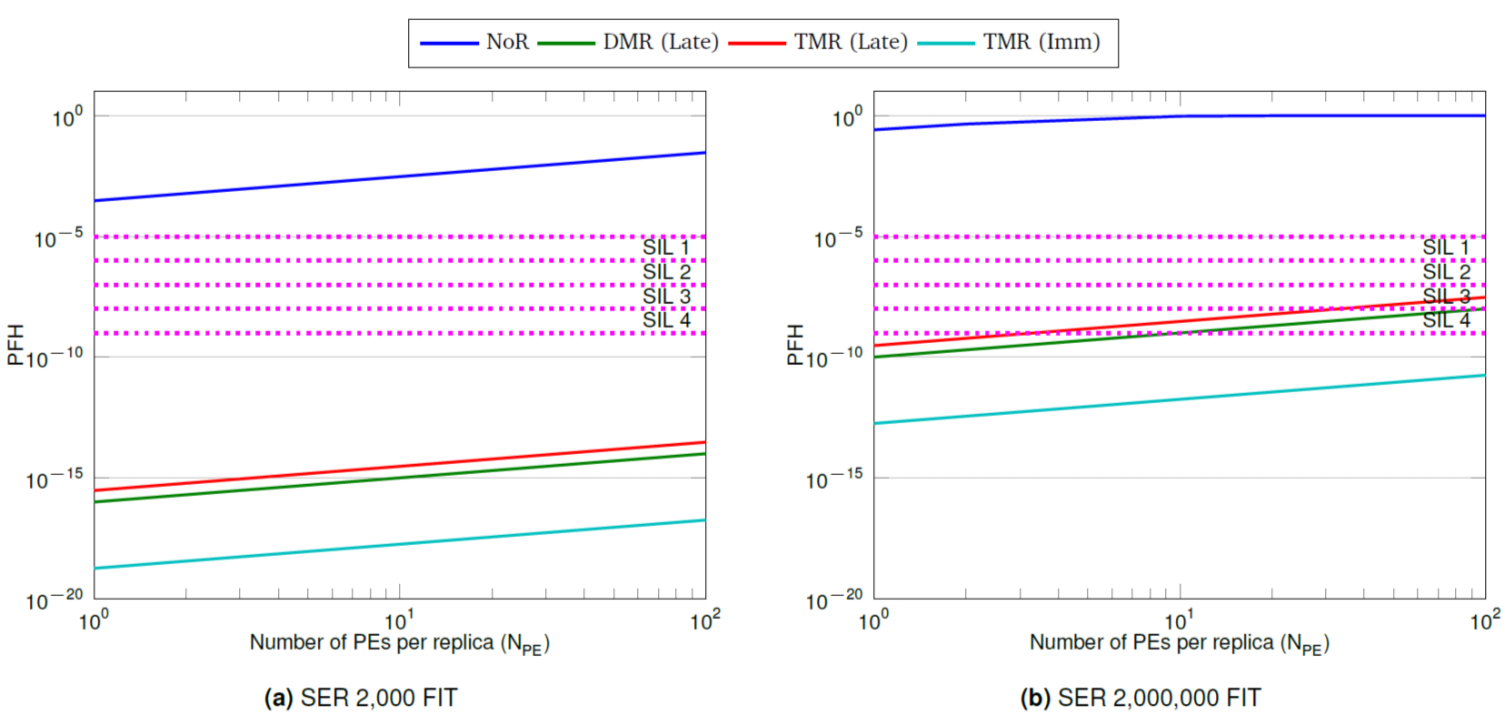
Probability of failure per hour (PFH) for a matrix-matrix multiplication loop nest application of size [200x400][400x300] based on the number of PEs for different soft error rates, i.e., 2,000 FIT and 2,000,000 FIT for the cases of no replication (blue), DMR with late comparison (DMR (Late), green), TMR with late voting (TMR (Late), red), and finally TMR with immediate voting (TMR (Imm), cyan).
Furthermore, in a tight collaboration with Project C1 and Project C3, we have developed hardware/software signalling mechanisms to provide feedback on loop executions on TCPAs, e.g., execution failures. Such feedback is provided as the return value of an infect request. It describes whether the execution on the invaded TCPA has failed, e.g., due to a computation failure, and which component was influenced by a fault. In order to realise such a capability, we have designed and integrated a so-called error handling unit (EHU) within each processing element (PE) that is capable of making majority votes (or comparison) over values within PE's register file.
Ultra-low power/dark silicon
Energy reduction and heterogeneous processing are central weapons to fight against the emerging problem of dark silicon. In the latter area, we were able to show that TCPAs provide an excellent IP in accelerator-rich MPSoCs by not only being able to save dynamic, but also static power by powering a claimed TCPA region up only at invade time. TCPAs have thereby proven to not only offer high performance but high energy efficiency in running compute-intensive loop kernels as well compared to general purpose processors. In order to exploit this capability within heterogeneous multiprocessor system-on-chip architectures, we have investigated particular techniques for power density-aware resource management for heterogeneous tiled multicores. In cooperation with Project B3, we investigated a power density-aware resource management for maximising the overall system performance on heterogeneous tiled multicores, where all cores or accelerators (\ie TCPAs) inside a tile share the same voltage and frequency levels, without violating a predefined critical temperature. Our technique considers power properties of applications as well as processors and consists of three steps defined as: (a) uniform power density constraints, (b) application assignment and mapping under power density constraints, and (c) run-time power density adaptation.
Orthogonal instruction processing
In general, system-on-chip architectures such as TCPAs have only access to a limited amount of memory, which stands in contrast to the characteristic of VLIW compilers that typically produce lengthy code, especially when employing software pipelining in loop programs. Therefore, we investigated a new processor architecture called Orthogonal Instruction Processing (OIP) that tackles this problem. The principle of this architecture that has been in the focus of our research is shown in the figure below.
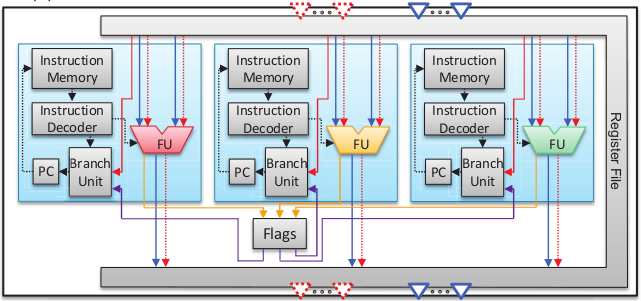
A processing element (PE) with an orthogonal instruction processing (OIP) architecture including three functional units (FU). Each FU has a dedicated instruction memory along with an instruction decoder, a program counter and a branch unit. The FUs share input and output interfaces as well as the register file. Additionally, each FU can access the flags of all FUs. The figure depicts the data and control flows inside a PE by blue and red connections, respectively. The flag logic is depicted by yellow connections.
Instead of a conventional VLIW processor that loads each cycle a very long instruction word from a single instruction memory, the major idea of OIP is to assign each FU its own instruction memory and branch unit. However, the register files as well as the flag distribution are still shared among all FUs. Our results show that considerable instruction memory savings become possible for many compute-intensive loop applications when changing from a VLIW architecture to an OIP architecture, while the savings easily outweigh a potential small hardware overhead for individual instruction pointers.
A comprehensive summary of the major achievements of the first and second funding phase can be found by accessing Project B2 first phase and Project B2 second phase websites.
Publications
| [1] | Jürgen Teich, Marcel Brand, Frank Hannig, Christian Heidorn, Dominik Walter, and Michael Witterauf. Invasive tightly-coupled processor arrays. In Jürgen Teich, Jörg Henkel, and Andreas Herkersdorf, editors, Invasive Computing, pages 177–202. FAU University Press, August 16, 2022. [ DOI ] |
| [2] | Nidhi Anantharajaiah, Tamim Asfour, Michael Bader, Lars Bauer, Jürgen Becker, Simon Bischof, Marcel Brand, Hans-Joachim Bungartz, Christian Eichler, Khalil Esper, Joachim Falk, Nael Fasfous, Felix Freiling, Andreas Fried, Michael Gerndt, Michael Glaß, Jeferson Gonzalez, Frank Hannig, Christian Heidorn, Jörg Henkel, Andreas Herkersdorf, Benedict Herzog, Jophin John, Timo Hönig, Felix Hundhausen, Heba Khdr, Tobias Langer, Oliver Lenke, Fabian Lesniak, Alexander Lindermayr, Alexandra Listl, Sebastian Maier, Nicole Megow, Marcel Mettler, Daniel Müller-Gritschneder, Hassan Nassar, Fabian Paus, Alexander Pöppl, Behnaz Pourmohseni, Jonas Rabenstein, Phillip Raffeck, Martin Rapp, Santiago Narváez Rivas, Mark Sagi, Franziska Schirrmacher, Ulf Schlichtmann, Florian Schmaus, Wolfgang Schröder-Preikschat, Tobias Schwarzer, Mohammed Bakr Sikal, Bertrand Simon, Gregor Snelting, Jan Spieck, Akshay Srivatsa, Walter Stechele, Jürgen Teich, Furkan Turan, Isaías A. Comprés Ureña, Ingrid Verbauwhede, Dominik Walter, Thomas Wild, Stefan Wildermann, Mario Wille, Michael Witterauf, and Li Zhang. Invasive Computing. FAU University Press, August 16, 2022. [ DOI ] |
| [3] | Christian Heidorn, Nicolai Meyerhöfer, Christian Schinabeck, Frank Hannig, and Jürgen Teich. Hardware-Aware Evolutionary Filter Pruning. In International Conference on Embedded Computer Systems: Architectures, Modeling and Simulation (SAMOS), July 2022. [ DOI ] |
| [4] | Marcel Brand, Frank Hannig, Oliver Keszocze, and Jürgen Teich. Precision- and accuracy-reconfigurable processor architectures – an overview. IEEE Transactions on Circuits and Systems II: Express Briefs, 69(6):2661–2666, 2022. [ DOI ] |
| [5] | Dominik Walter and Jürgen Teich. LION: Real-time I/O transfer control for massively parallel processor arrays. In Proceedings of the 19th ACM-IEEE International Conference on Formal Methods and Models for System Design (MEMOCODE), pages 32–43. Association for Computing Machinery, November 2021. [ DOI ] |
| [6] | Jürgen Teich. Enforcement of non-functional program requirements on MPSOCs. Keynote, HiPEAC Computing Week, Lyon, France, October 25, 2021. |
| [7] | Armin Schuster, Christian Heidorn, Marcel Brand, Oliver Keszöcze, and Jürgen Teich. Design space exploration of time, energy, and error rate trade-offs for CNNs using accuracy-programmable instruction set processors. In Joint European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD), September 2021. [ DOI ] |
| [8] | Christian Heidorn, Dominik Walter, Yunus Emre Candir, Frank Hannig, and Jürgen Teich. Hand sign recognition via deep learning on tightly coupled processor arrays. In Proceedings of the 31st International Conference on Field-Programmable Logic and Applications (FPL), page 388. IEEE, August 2021. [ DOI ] |
| [9] | Oliver Keszöcze, Marcel Brand, Michael Witterauf, Christian Heidorn, and Jürgen Teich. Aarith: An Arbitrary Precision Number Library. In ACM/SIGAPP Symposium On Applied Computing, 2021. [ DOI ] |
| [10] | Dominik Walter, Michael Witterauf, and Jürgen Teich. Real-time scheduling of I/O transfers for massively parallel processor arrays. In Proceedings of the 18th ACM-IEEE International Conference on Formal Methods and Models for System Design (MEMOCODE), pages 1–11. IEEE, December 2020. [ DOI ] |
| [11] | T. K. R. Arvind, Marcel Brand, Christian Heidorn, Srinivas Boppu, Frank Hannig, and Jürgen Teich. Hardware implementation of hyperbolic tangent activation function for floating point formats. In Proceedings of the 24th International Symposium on VLSI Design and Test (VDAT). IEEE, July 2020. [ DOI ] |
| [12] | Frank Hannig, Javier Navaridas, Dirk Koch, and Ameer Abdelhadi, editors. Proceedings of the 31st IEEE International Conference on Application-specific Systems, Architectures and Processors (ASAP). IEEE Computer Society, July 2020. [ DOI ] |
| [13] | Marcel Brand, Michael Witterauf, Alberto Bosio, and Jürgen Teich. Anytime floating-point addition and multiplication – Concepts and implementations. In Proceedings of the 31st IEEE International Conference on Application-specific Systems, Architectures and Processors (ASAP), pages 157–164. IEEE, July 2020. [ DOI ] |
| [14] | Christian Heidorn, Frank Hannig, and Jürgen Teich. Design space exploration for layer-parallel execution of convolutional neural networks on CGRAs. In Proceedings of the 23rd International Workshop on Software and Compilers for Embedded Systems (SCOPES), pages 26–31. ACM, May 2020. [ DOI ] |
| [15] | Christian Heidorn, Michael Witterauf, Frank Hannig, and Jürgen Teich. CNN-inference on coarse-grained reconfigurable arrays under throughput constraints. Invited talk, 4th Tensilica Day – Trends in Modern Design of Configurable Processors, Leibnitz University Hannover, Germany, September 23, 2019. |
| [16] | Jürgen Teich. Efficient treatment of uncertainty in system reliability analysis using importance measures. Invited Talk at the Workshop Intelligent Methods for Test and Reliability, Schloss Dagstuhl, September 12, 2019. |
| [17] | Faramarz Khosravi. System-Level Reliability Analysis and Optimization in the Presence of Uncertainty. Dissertation, Hardware/Software Co-Design, Department of Computer Science, Friedrich-Alexander-Universität Erlangen-Nürnberg, Germany, August 5, 2019. |
| [18] | Christian Heidorn, Michael Witterauf, Frank Hannig, and Jürgen Teich. Efficient mapping of CNNs onto tightly coupled processor arrays. Journal of Computers (JCP), 14(8):541–556, August 2019. [ DOI ] |
| [19] | Marcel Brand, Michael Witterauf, Frank Hannig, and Jürgen Teich. Anytime instructions for programmable accuracy floating-point arithmetic. In Proceedings of the ACM International Conference on Computing Frontiers (CF), pages 215–219. ACM, April 2019. [ DOI ] |
| [20] | Marcel Brand, Michael Witterauf, Éricles R. Sousa, Alexandru Tanase, Frank Hannig, and Jürgen Teich. *-Predictable MPSoC execution of real-time control applications using invasive computing. Concurrency and Computation: Practice and Experience, February 2019. [ DOI ] |
| [21] | Jürgen Teich. Run-time application mapping in many-core architectures. Invited Talk National University of Singapore, August 24, 2018. |
| [22] | Jürgen Teich. Mixed static/dynamic application mapping for NoC-based MPSoCs with guarantees on timing, reliability and security. Invited Talk Nanyang Technological University, Singapore, August 23, 2018. |
| [23] | Jürgen Teich. Hybrid application mapping for NoC-based MPSoCs with guarantees on timing, reliability and security. Invited Talk University of New South Wales, Australia, July 31, 2018. |
| [24] | Éricles R. Sousa. Memory and Interface Architectures for Invasive Tightly Coupled Processor Arrays. Dissertation, Hardware/Software Co-Design, Department of Computer Science, Friedrich-Alexander-Universität Erlangen-Nürnberg, Germany, July 20, 2018. |
| [25] | Éricles R. Sousa, Michael Witterauf, Marcel Brand, Alexandru Tanase, Frank Hannig, and Jürgen Teich. Invasive computing for predictability of multiple non-functional properties: A cyber-physical system case study. In Proceedings of the 29th Annual IEEE International Conference on Application-specific Systems, Architectures and Processors (ASAP). IEEE, July 2018. [ DOI ] |
| [26] | Jürgen Teich. Methodologies for application mapping for noc-based mpsocs. Keynote, Adaptive Many-Core Architectures and Systems workshop, York, UK, June 14, 2018. |
| [27] | Christian Schmitt, Frank Hannig, and Jürgen Teich. A Target Platform Description Language for Parallel Code Generation. In Workshop Proceedings of the 31st GI/ITG International Conference on Architecture of Computing Systems (ARCS), pages 59–66, Berlin, April 2018. VDE VERLAG GmbH. |
| [28] | Alexandru Tanase, Frank Hannig, and Jürgen Teich. Symbolic Parallelization of Nested Loop Programs. Springer, February 2018. [ DOI ] |
| [29] | Andreas Weichslgartner, Stefan Wildermann, Michael Glaß, and Jürgen Teich. Invasive Computing for Mapping Parallel Programs to Many-Core Architectures. Springer, January 15, 2018. [ DOI ] |
| [30] | Éricles Sousa, Arindam Chakraborty, Alexandru Tanase, Frank Hannig, and Jürgen Teich. TCPA Editor: A design automation environment for a class of coarse-grained reconfigurable arrays. Demo Night at the International Conference on Reconfigurable Computing and FPGAs (ReConFig), December 2017. |
| [31] | Éricles Sousa, Alexandru Tanase, Frank Hannig, and Jürgen Teich. A reconfigurable memory architecture for system integration of coarse-grained reconfigurable arrays. In Proceedings of the International Conference on Reconfigurable Computing and FPGAs (ReConFig). IEEE, December 2017. [ DOI ] |
| [32] | Marcel Brand, Frank Hannig, Alexandru Tanase, and Jürgen Teich. Orthogonal instruction processing: An alternative to lightweight VLIW processors. In Proceedings of the IEEE 11th International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSoC), pages 5–12. IEEE Computer Society, September 2017. [ DOI ] |
| [33] | Marcel Brand, Frank Hannig, Alexandru Tanase, and Jürgen Teich. Efficiency in ILP processing by using orthogonality. In Proceedings of the 28th Annual IEEE International Conference on Application-specific Systems, Architectures and Processors (ASAP), page 207. IEEE, July 2017. [ DOI ] |
| [34] | Heba Khdr, Santiago Pagani, Éricles R. Sousa, Vahid Lari, Anuj Pathania, Frank Hannig, Muhammad Shafique, Jürgen Teich, and Jörg Henkel. Power density-aware resource management for heterogeneous tiled multicores. IEEE Transactions on Computers (TC), 66(3):488–501, March 1, 2017. [ DOI ] |
| [35] | Soonhoi Ha and Jürgen Teich, editors. The Handbook of Hardware/Software Codesign. Springer, 2017. [ DOI ] |
| [36] | Alexandru Tanase, Michael Witterauf, Jürgen Teich, and Frank Hannig. Symbolic multi-level loop mapping of loop programs for massively parallel processor arrays. ACM Transactions on Embedded Computing Systems (TECS), 17(2):31:1–31:27, 2017. [ DOI ] |
| [37] | Jürgen Teich. Invasive computing – editorial. it – Information Technology, 58(6):263–265, November 24, 2016. [ DOI ] |
| [38] | Vahid Lari, Andreas Weichslgartner, Alex Tanase, Michael Witterauf, Faramarz Khosravi, Jürgen Teich, Jürgen Becker, Jan Heißwolf, and Stephanie Friederich. Providing fault tolerance through invasive computing. it – Information Technology, 58(6):309–328, October 19, 2016. [ DOI ] |
| [39] | Santiago Pagani, Lars Bauer, Qingqing Chen, Elisabeth Glocker, Frank Hannig, Andreas Herkersdorf, Heba Khdr, Anuj Pathania, Ulf Schlichtmann, Doris Schmitt-Landsiedel, Mark Sagi, Éricles Sousa, Philipp Wagner, Volker Wenzel, Thomas Wild, and Jörg Henkel. Dark silicon management: An integrated and coordinated cross-layer approach. it – Information Technology, 58(6):297–307, September 16, 2016. [ DOI ] |
| [40] | Jürgen Teich, Michael Glaß, Sascha Roloff, Wolfgang Schröder-Preikschat, Gregor Snelting, Andreas Weichslgartner, and Stefan Wildermann. Language and compilation of parallel programs for *-predictable MPSoC execution using invasive computing. In Proceedings of the 10th IEEE International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSoC), pages 313–320, Lyon, France, September 2016. [ DOI ] |
| [41] | Jürgen Teich. Predictability, fault tolerance, and security on demand using invasive computing. Invited Talk, University of Lübeck, Germany, July 29, 2016. |
| [42] | Vahid Lari. Providing fault tolerance through invasive computing. Talk at DTC 2016, The Munich Workshop on Design Technology Coupling, Munich, Germany, June 30, 2016. |
| [43] | Jürgen Teich. Invasive Computing - The DFG Transregional Research Center 89. DTC 2016, The Munich Workshop on Design Technology Coupling, Munich, Germany, June 30, 2016. |
| [44] | Jürgen Teich. Predictable MPSoC stream processing using invasive computing. Seminar Talk, Electrical and Computer Engineering, The University of Texas at Austin, USA, June 6, 2016. |
| [45] | Jürgen Teich. Adaptive restriction and isolation for predictable MPSoC stream procesing. Invited Talk, DATE 2016 Friday Workshop on Resource Awareness and Application Autotuning in Adaptive and Heterogeneous Computing, Dresden, Germany, March 18, 2016. |
| [46] | Alexandru Tanase, Michael Witterauf, Éricles R. Sousa, Vahid Lari, Frank Hannig, and Jürgen Teich. LoopInvader: A compiler for tightly coupled processor arrays. Tool Presentation at the University Booth at Design, Automation and Test in Europe (DATE), Dresden, Germany, March 2016. [ .pdf ] |
| [47] | Jürgen Teich. Symbolic loop parallelization for adaptive multi-core systems - recent advances and benefits. Keynote, IMPACT 2016, the 6th International Workshop on Polyhedral Compilation Techniques, 19 January, 2016, Prague, Czech Republic, January 19, 2016. |
| [48] | Jürgen Teich. The role of restriction and isolation for increasing the predictability of MPSoC stream processing. Keynote, 8th Workshop on Rapid Simulation and Performance Evaluation: Methods and Tools (RAPIDO 2016), Prague, Czech Republic, January 18, 2016. |
| [49] | Vahid Lari. Invasive Tightly Coupled Processor Arrays. Springer Singapore, 2016. [ DOI ] |
| [50] | Srinivas Boppu. Code Generation for Tightly Coupled Processor Arrays. Dissertation, Hardware/Software Co-Design, Department of Computer Science, Friedrich-Alexander-Universität Erlangen-Nürnberg, Germany, December 18, 2015. |
| [51] | Oliver Reiche, Konrad Häublein, Marc Reichenbach, Moritz Schmid, Frank Hannig, Jürgen Teich, and Dietmar Fey. Synthesis and optimization of image processing accelerators using domain knowledge. Journal of Systems Architecture (JSA), December 2015. [ DOI ] |
| [52] | Vahid Lari. Invasive Tightly Coupled Processor Arrays. Dissertation, Hardware/Software Co-Design, Department of Computer Science, Friedrich-Alexander-Universität Erlangen-Nürnberg, Germany, November 18, 2015. |
| [53] | Éricles R. Sousa, Frank Hannig, and Jürgen Teich. Reconfigurable buffer structures for coarse-grained reconfigurable arrays. In Proceedings of the International Embedded Systems Symposium (IESS). LNCS, November 2015. |
| [54] | Johny Paul, Walter Stechele, Benjamin Oechslein, Christoph Erhardt, Jens Schedel, Daniel Lohmann, Wolfgang Schröder-Preikschat, Manfred Kröhnert, Tamim Asfour, Éricles R. Sousa, Vahid Lari, Frank Hannig, Jürgen Teich, Artjom Grudnitsky, Lars Bauer, and Jörg Henkel. Resource-awareness on heterogeneous MPSoCs for image processing. Journal of Systems Architecture, 61(10):668–680, November 6, 2015. [ DOI ] |
| [55] | Vahid Lari, Jürgen Teich, Alexandru Tanase, Michael Witterauf, Faramarz Khosravi, and Brett H. Meyer. Techniques for on-demand structural redundancy for massively parallel processor arrays. Journal of Systems Architecture (JSA), 61(10):615–627, November 2015. [ DOI ] |
| [56] | Moritz Schmid. Rapid Prototyping for Hardware Accelerators in the Medical Imaging Domain. Dissertation, Hardware/Software Co-Design, Department of Computer Science, Friedrich-Alexander-Universität Erlangen-Nürnberg, Germany, July 24, 2015. |
| [57] | Alexandru Tanase, Michael Witterauf, Jürgen Teich, Frank Hannig, and Vahid Lari. On-demand fault-tolerant loop processing on massively parallel processor arrays. In Proceedings of the 26th IEEE International Conference on Application-specific Systems, Architectures and Processors (ASAP), pages 194–201. IEEE, July 2015. [ DOI ] |
| [58] | Moritz Schmid, Oliver Reiche, Frank Hannig, and Jürgen Teich. Loop coarsening in C-based high-level synthesis. In Proceedings of the 26th IEEE International Conference on Application-specific Systems, Architectures and Processors (ASAP), pages 166–173. IEEE, July 2015. |
| [59] | Michael Witterauf, Alexandru Tanase, Jürgen Teich, Vahid Lari, Andreas Zwinkau, and Gregor Snelting. Adaptive fault tolerance through invasive computing. In Proceedings of the 2015 NASA/ESA Conference on Adaptive Hardware and Systems (AHS), pages 1–8. IEEE, June 2015. [ DOI ] |
| [60] | Jürgen Teich. Adaptive isolation for predictable mpsoc stream processing. In Proceedings of the 18th International Workshop on Software and Compilers for Embedded Systems (SCOPES 2015), pages 1–2, June 2015. [ DOI ] |
| [61] | Jürgen Teich. Adaptive isolation for predictable mpsoc stream processing. Keynote, SCOPES 2015, 18th International Workshop on Software and Compilers for Embedded Systems, Schloss Rheinfels, St. Goar, Germany, June 2, 2015. |
| [62] | Éricles R. Sousa, Frank Hannig, Jürgen Teich, Qingqing Chen, and Ulf Schlichtmann. Runtime adaptation of application execution under thermal and power constraints in massively parallel processor arrays. In Proceedings of the 18th International Workshop on Software and Compilers for Embedded Systems (SCOPES), pages 121–124. ACM, June 2015. [ DOI ] |
| [63] | Vahid Lari, Alexandru Tanase, Jürgen Teich, Michael Witterauf, Faramarz Khosravi, Frank Hannig, and Brett H. Meyer. A co-design approach for fault-tolerant loop execution on coarse-grained reconfigurable arrays. In Proceedings of the 2015 NASA/ESA Conference on Adaptive Hardware and Systems (AHS), pages 1–8. IEEE, June 2015. [ DOI ] |
| [64] | Jürgen Teich, Srinivas Boppu, Frank Hannig, and Vahid Lari. Compact code generation and throughput optimization for coarse-grained reconfigurable arrays. In Wayne Luk and George A. Constantinides, editors, Transforming Reconfigurable Systems: A Festschrift Celebrating the 60th Birthday of Professor Peter Cheung, chapter 10, pages 167–206. Imperial College Press, London, UK, April 2015. [ DOI ] |
| [65] | Jürgen Teich. Invasive computing. Invited Talk, SE 2015, Software Engineering and Management, Special Session Software Engineering in der DFG, Dresden, Germany, March 19, 2015. |
| [66] | Jürgen Teich. Reconfigurable computing for mpsoc. Invited Lecture, Winter School Design and Applications of Multi Processor System on Chip, Tunis, Tunesia, November 26, 2014. |
| [67] | Deepak Gangadharan, Éricles Sousa, Vahid Lari, Frank Hannig, and Jürgen Teich. Application-driven reconfiguration of shared resources for timing predictability of mpsoc platforms. In Proceedings of Asilomar Conference on Signals, Systems, and Computers (ASILOMAR), pages 398–403. IEEE, November 2014. [ DOI ] |
| [68] | Jürgen Teich. Invasive computing – concepts and benefits. Keynote, DASIP 2014, Conference on Design and Architectures for Signal and Image Processing, Madrid, Spain, October 8, 2014. |
| [69] | Johny Paul, Walter Stechele, Éricles R. Sousa, Vahid Lari, Frank Hannig, Jürgen Teich, Manfred Kröhnert, and Tamim Asfour. Self-adaptive harris corner detector on heterogeneous many-core processor. In Proceedings of the Conference on Design and Architectures for Signal and Image Processing (DASIP). IEEE, October 2014. [ DOI ] |
| [70] | Éricles Sousa, Deepak Gangadharan, Frank Hannig, and Jürgen Teich. Runtime reconfigurable bus arbitration for concurrent applications on heterogeneous MPSoC architectures. In Proceedings of the EUROMICRO Digital System Design Conference (DSD), pages 74–81. IEEE, August 2014. [ DOI ] |
| [71] | Jürgen Teich. Foundations and benefits of invasive computing. Seminar, Mc Gill University, Montreal, July 29, 2014. |
| [72] | Srinivas Boppu, Frank Hannig, and Jürgen Teich. Compact code generation for tightly-coupled processor arrays. Journal of Signal Processing Systems, 77(1–2):5–29, May 31, 2014. [ DOI ] |
| [73] | Jürgen Teich. Introduction to invasive computing. Workshop on Resource Awareness and Adaptivity in Multi-Core Computing (Racing 2014), Paderborn, Germany, Tutorial Talk, May 29, 2014. |
| [74] | Jürgen Teich. Foundations and benefits of invasive computing. University of Bologna, Italy, Invited Talk in the Seminar Series Trends in Electronics, May 23, 2014. |
| [75] | Frank Hannig and Jürgen Teich, editors. Proceedings of the First Workshop on Resource Awareness and Adaptivity in Multi-Core Computing (Racing 2014). May 2014. [ arXiv ] |
| [76] | Vahid Lari, Alexandru Tanase, Frank Hannig, and Jürgen Teich. Massively parallel processor architectures for resource-aware computing. In Proceedings of the First Workshop on Resource Awareness and Adaptivity in Multi-Core Computing (Racing 2014), pages 1–7, May 2014. [ arXiv ] |
| [77] | Deepak Gangadharan, Alexandru Tanase, Frank Hannig, and Jürgen Teich. Timing analysis of a heterogeneous architecture with massively parallel processor arrays. In DATE Friday Workshop on Performance, Power and Predictability of Many-Core Embedded Systems (3PMCES). ECSI, March 28, 2014. [ http ] |
| [78] | Éricles Sousa, Vahid Lari, Johny Paul, Frank Hannig, Jürgen Teich, and Walter Stechele. Resource-aware computer vision application on heterogeneous multi-tile architecture. Hardware and Software Demo at the University Booth at Design, Automation and Test in Europe (DATE), Dresden, Germany, March 2014. |
| [79] | Frank Hannig, Vahid Lari, Srinivas Boppu, Alexandru Tanase, and Oliver Reiche. Invasive tightly-coupled processor arrays: A domain-specific architecture/compiler co-design approach. ACM Transactions on Embedded Computing Systems (TECS), 13(4s):133:1–133:29, 2014. [ DOI ] |
| [80] | Jürgen Teich. Invasive computing – the quest for many-core efficiency and predictability. Keynote Talk, Sixth Swedish Workshop on Multicore Computing, Halmstad, Sweden, November 25, 2013. |
| [81] | Jürgen Teich. Invasive computing - the quest for many-core efficiency and predictability. Invited Talk, 5th tubs.CITY Symposium, Managing change and autonomy or critical applications, Braunschweig, Germany, October 30, 2013. |
| [82] | Éricles Sousa, Alexandru Tanase, Frank Hannig, and Jürgen Teich. A prototype of an adaptive computer vision algorithm on an MPSoC architecture. In Proceedings of the Conference on Design and Architectures for Signal and Image Processing (DASIP), pages 361–362. IEEE, October 2013. |
| [83] | Éricles Sousa, Alexandru Tanase, Frank Hannig, and Jürgen Teich. Accuracy and performance analysis of harris corner computation on tightly-coupled processor arrays. In Proceedings of the Conference on Design and Architectures for Signal and Image Processing (DASIP), pages 88–95. IEEE, October 2013. |
| [84] | Jürgen Teich. The invasive computing paradigm as a solution for highly adaptive and efficient multi-core systems. Talk, Special Session on Run-Time Adaption for Highly-Compley Multi-Core Systems, CODES+ISSS 2013, Montral, Canada, September 30, 2013. |
| [85] | Alexandru Tanase, Vahid Lari, Frank Hannig, and Jürgen Teich. Exploitation of quality/throughput tradeoffs in image processing through invasive computing. In Proceedings of the International Conference on Parallel Computing (ParCo), pages 53–62, September 2013. [ DOI ] |
| [86] | Elisabeth Glocker, Srinivas Boppu, Qingqing Chen, Ulf Schlichtmann, Jürgen Teich, and Doris Schmitt-Landsiedel. Temperature modeling and emulation of an ASIC temperature monitor system for Tightly-Coupled Processor Arrays (TCPAs) on FPGA. In Kleinheubacher Tagung 2013, September 2013. |
| [87] | Vahid Lari, Srinivas Boppu, Frank Hannig, Jürgen Teich, and Troy Scott. Hybrid prototyping of tightly-coupled processor arrays for MPSoC designs. Designer Track Poster Presentation at the 50th Design Automation Conference (DAC), Austin, TX, USA, June 2013. |
| [88] | Srinivas Boppu, Frank Hannig, and Jürgen Teich. Loop program mapping and compact code generation for programmable hardware accelerators. In Proceedings of the 24th IEEE International Conference on Application-specific Systems, Architectures and Processors (ASAP), pages 10–17. IEEE, June 2013. [ DOI ] |
| [89] | Srinivas Boppu, Vahid Lari, Frank Hannig, and Jürgen Teich. Transactor-based prototyping of heterogeneous multiprocessor system-on-chip architectures. In Proceedings of the Synopsys Users Group Conference (SNUG), May 14, 2013. |
| [90] | Frank Hannig, Moritz Schmid, Vahid Lari, Srinivas Boppu, and Jürgen Teich. System integration of tightly-coupled processor arrays using reconfigurable buffer structures. In Proceedings of the ACM International Conference on Computing Frontiers (CF), pages 2:1–2:4. ACM, May 2013. [ DOI ] |
| [91] | Éricles Sousa, Alexandru Tanase, Vahid Lari, Frank Hannig, Jürgen Teich, Johny Paul, Walter Stechele, Manfred Kröhnert, and Tamim Asfour. Acceleration of optical flow computations on tightly-coupled processor arrays. In Proceedings of the 25th Workshop on Parallel Systems and Algorithms (PARS), volume 30 of Mitteilungen – Gesellschaft für Informatik e. V., Parallel-Algorithmen und Rechnerstrukturen, pages 80–89. Gesellschaft für Informatik e.V., April 2013. |
| [92] | Vahid Lari, Srinivas Boppu, Frank Hannig, Shravan Muddasani, Boris Kuzmin, and Jürgen Teich. Resource-aware video processing on tightly-coupled processor arrays. Hardware and Software Demo at the University Booth at Design, Automation and Test in Europe (DATE), Grenoble, France, March 2013. [ .pdf ] |
| [93] | Frank Hannig. Resource-aware computing on domain-specific accelerators. In Proceedings of the 10st Workshop on Optimizations for DSP and Embedded Systems (ODES), page 35. ACM, February 24, 2013. Keynote. [ DOI ] |
| [94] | Jürgen Teich. Safe(r) loop computations on multi-cores. Invited Talk, 2nd Workshop on Design Tools and Architectures for Multi-Core Embedded Computing Platforms (DITAM 2013), Berlin, Germany, January 22, 2013. |
| [95] | Vahid Lari, Shravan Muddasani, Srinivas Boppu, Frank Hannig, Moritz Schmid, and Jürgen Teich. Hierarchical power management for adaptive tightly-coupled processor arrays. ACM Transactions on Design Automation of Electronic Systems (TODAES), 18(1):2:1–2:25, January 2013. [ DOI ] |
| [96] | Frank Hannig. Why do we see more and more domain-specific accelerators in multi-processor systems? Guest Lecture at University of California, Riverside in CS 287 Colloquium in Computer Science, Riverside, CA, USA, November 9, 2012. |
| [97] | Frank Hannig. Invasive tightly-coupled processor arrays. Talk, 1st International Workshop on Domain-Specific Multicore Computing (DSMC) at International Conference on Computer-Aided Design (ICCAD), San Jose, CA, USA, November 8, 2012. |
| [98] | Shravan Muddasani, Srinivas Boppu, Frank Hannig, Boris Kuzmin, Vahid Lari, and Jürgen Teich. A prototype of an invasive tightly-coupled processor array. In Proceedings of the Conference on Design and Architectures for Signal and Image Processing (DASIP), pages 393–394. IEEE, October 2012. |
| [99] | Vahid Lari, Shravan Muddasani, Srinivas Boppu, Frank Hannig, and Jürgen Teich. Design of low power on-chip processor arrays. In Proceedings of the 23rd IEEE International Conference on Application-specific Systems, Architectures, and Processors (ASAP), pages 165–168. IEEE Computer Society, July 2012. [ DOI ] |
| [100] | Jürgen Teich. Hardware/software co-design: The past, present, and predicting the future. Proceedings of the IEEE, 100(Centennial-Issue):1411–1430, May 2012. [ DOI ] |
| [101] | Jörg Henkel, Andreas Herkersdorf, Lars Bauer, Thomas Wild, Michael Hübner, Ravi Kumar Pujari, Artjom Grudnitsky, Jan Heisswolf, Aurang Zaib, Benjamin Vogel, Vahid Lari, and Sebastian Kobbe. Invasive manycore architectures. In Proceedings of the 17th Asia and South Pacific Design Automation Conference (ASP-DAC), pages 193–200, January 2012. [ DOI ] |
| [102] | Vahid Lari, Srinivas Boppu, Shravan Muddasani, Frank Hannig, and Jürgen Teich. Hierarchical power management for adaptive tightly-coupled processor arrays. Talk, International Workshop on Adaptive Power Management with Machine Intelligence at International Conference on Computer-Aided Design (ICCAD), San Jose, CA, USA, November 10, 2011. |
| [103] | Srinivas Boppu, Frank Hannig, Jürgen Teich, and Roberto Perez-Andrade. Towards symbolic run-time reconfiguration in tightly-coupled processor arrays. In Proceedings of the International Conference on Reconfigurable Computing and FPGAs (ReConFig), pages 392–397. IEEE, November 2011. [ DOI ] |
| [104] | Vahid Lari, Andriy Narovlyanskyy, Frank Hannig, and Jürgen Teich. Decentralized dynamic resource management support for massively parallel processor arrays. In Proceedings of the 22nd IEEE International Conference on Application-specific Systems, Architectures and Processors (ASAP), pages 87–94. IEEE Computer Society, September 2011. [ DOI ] |
| [105] | Vahid Lari, Frank Hannig, and Jürgen Teich. Distributed resource reservation in massively parallel processor arrays. In Proceedings of the International Parallel and Distributed Processing Symposium Workshops (IPDPSW), pages 318–321. IEEE Computer Society, May 2011. [ DOI ] |
| [106] | Josef Angermeier, Eugen Sibirko, Rolf Wanka, and Jürgen Teich. Bitonic sorting on dynamically reconfigurable architectures. In Proceedings of the International Parallel and Distributed Processing Symposium Workshops (IPDPSW), pages 309–312, May 2011. |
| [107] | Jürgen Teich, Jörg Henkel, Andreas Herkersdorf, Doris Schmitt-Landsiedel, Wolfgang Schröder-Preikschat, and Gregor Snelting. Invasive computing: An overview. In Michael Hübner and Jürgen Becker, editors, Multiprocessor System-on-Chip – Hardware Design and Tool Integration, pages 241–268. Springer, Berlin, Heidelberg, 2011. [ DOI ] |
| [108] | Dmitrij Kissler, Daniel Gran, Zoran A. Salcic, Frank Hannig, and Jürgen Teich. Scalable many-domain power gating in coarse-grained reconfigurable processor arrays. IEEE Embedded Systems Letters, 3(2):58–61, 2011. [ DOI ] |
| [109] | Tom Vander Aa, Praveen Raghavan, Scott Mahlke, Bjorn De Sutter, Aviral Shrivastava, and Frank Hannig. Compilation techniques for CGRAs: Exploring all parallelization approaches. In Proceedings of the International Conference on Hardware-Software Codesign and System Synthesis (CODES+ISSS), pages 185–186. ACM, October 2010. [ DOI ] |
| [110] | Amouri Abdulazim, Farhadur Arifin, Frank Hannig, and Jürgen Teich. FPGA implementation of an invasive computing architecture. In Proceedings of the IEEE International Conference on Field Programmable Technology (FPT), pages 135–142. IEEE, December 2009. [ DOI ] |
| [111] | Farhadur Arifin, Richard Membarth, Amouri Abdulazim, Frank Hannig, and Jürgen Teich. FSM-controlled architectures for linear invasion. In Proceedings of the 17th IFIP/IEEE International Conference on Very Large Scale Integration (VLSI-SoC), pages 59–64, October 2009. [ DOI ] |
| [112] | Jürgen Teich. Invasive algorithms and architectures. it - Information Technology, 50(5):300–310, 2008. |